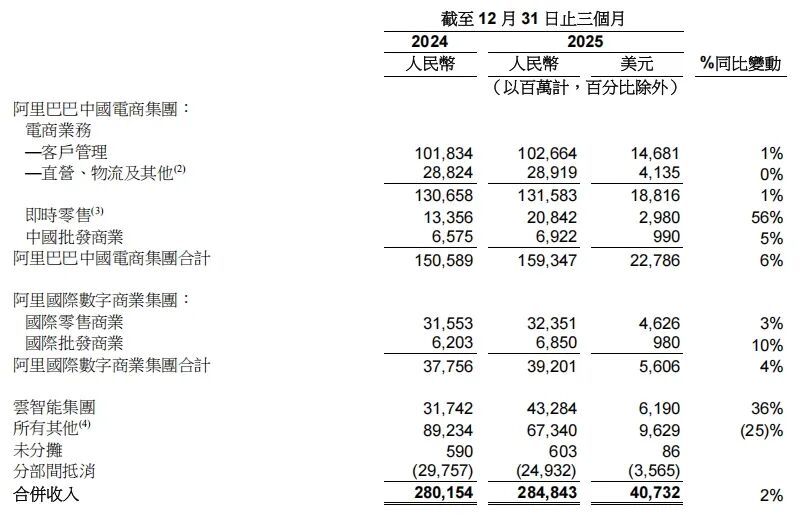
扩散模型面临的奖励作弊挑战
在当前的图像生成技术领域,扩散模型已经成为核心技术之一。从简单的文本到图像生成到复杂的视觉内容合成,这类模型能够生成高度逼真的画面。然而,在实际应用场景中,人们对生成模型的要求已经超越了单纯的"生成逼真图像",而是期望模型能够严格按照提示要求完成特定任务。

奖励作弊现象正成为生成模型对齐研究中的重要挑战。当要求生成包含指定文字的图像时,模型可能会简单地将文字放大到占据画面大部分区域,从而轻松获得OCR系统的高分。在需要生成多个对象的任务中,模型也可能通过极度简化场景结构来满足评分规则。这种投机行为虽然能够获得较高的自动评分,但实际生成的图像质量往往不尽人意。
GDRO方法的创新设计原理
GDRO方法的核心创新在于引入了组级奖励优化机制。与传统方法不同,GDRO采用完全离线的训练方式,在训练开始之前先生成并保存带有评分信息的图像数据。这种设计避免了重复执行扩散链带来的巨大计算成本,同时不依赖特定的扩散采样器,使训练流程更加简单稳定。
技术实现细节
在具体实现上,GDRO首先选择FLUX.1-dev作为基础模型。研究人员并没有重新训练整个模型,而是在这个预训练模型的基础上进行后训练优化,这样既节省了计算资源,又能将研究重点集中在奖励优化方法本身。

数据生成过程包括:对于每个提示词,使用基础模型生成16张图像;随后对每张图像计算奖励评分;最后根据奖励大小对这些图像进行排序。每个提示词都会对应一组带有评分信息的图像集合,这些图像组随后作为GDRO训练阶段使用的数据。
实验验证与性能分析
OCR任务表现
在OCR文字生成任务中,研究人员设置了包含约2万条提示词的训练集和约1000条提示词的测试集。这些提示词通常描述具体场景中包含指定文字的情况,例如"一个珠宝店橱窗,上面写着diamond sale"。
实验结果显示,原始模型生成的文字经常出现拼写错误、字体模糊、字符缺失以及排列混乱等问题。经过GDRO训练后,生成图片中的文字更加清晰,文字排版更加规范,OCR识别的准确率明显提高。
GenEval任务评估
GenEval任务主要评估模型对文本描述的理解能力,重点关注四个方面的能力:物体数量是否正确、物体属性是否正确、物体之间的位置关系是否正确,以及图像整体是否符合文本描述。
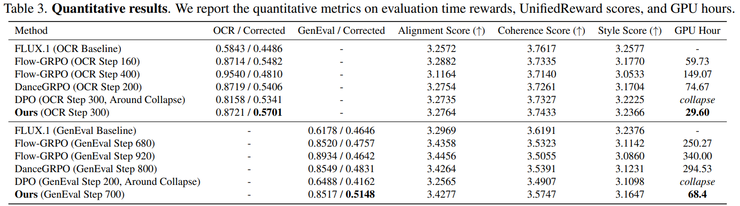
实验使用了包含约5万条提示词的训练集和约2000条提示词的测试集。提示词涉及多个对象、对象属性以及对象之间的空间关系,例如"一张黄色餐桌和一只粉色狗"、"一个笔记本电脑在球下面"等。结果显示,在使用GDRO训练之后,图像中的对象数量更加准确,对象之间的位置关系更加符合提示描述。
奖励作弊现象的深入分析
奖励作弊是指模型为了获得更高评分,并没有真正提高生成图像的质量,而是通过某种投机方式去欺骗评分系统。这种现象在当前的生成模型训练中普遍存在。
OCR任务中的作弊策略
在OCR任务中,一些强化学习方法会采取极端策略来提高OCR评分,例如把目标文字做得非常大,将文字放在图像中央位置,同时减少图像中的背景内容。虽然这种策略能够获得较高的OCR评分,但会导致图像整体变得不自然、背景细节消失以及图像结构被破坏。

GenEval任务中的简化倾向
在GenEval任务中,一些方法生成的图像会变得非常简单,只保留最基本的对象,同时几乎没有任何细节。例如在提示词为"一个绿色热狗"的情况下,生成的图像可能只有一个简单的图形,背景几乎为空。虽然对象类型正确,但整体图像质量明显下降。
人工评估验证
为了进一步验证自动评分系统的可靠性,研究团队进行了人工评估实验。实验邀请了21名参与者,对不同方法生成的图片进行比较评价。评价主要从文字准确性、图像与提示词之间的匹配程度以及图像整体质量三个方面进行。
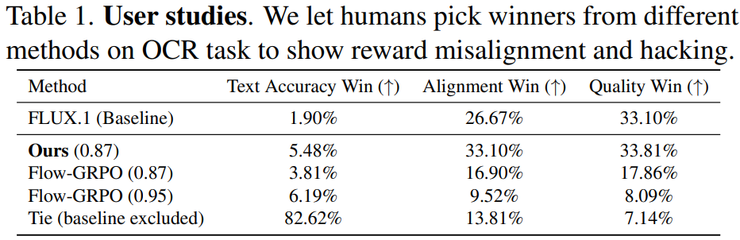
实验结果显示,在文字准确性方面,各种方法之间的差距并不明显,但在图像质量以及语义匹配方面,GDRO生成的图像表现明显更好。这证实了GDRO方法在提升图像质量方面的有效性。
训练效率的优势分析
传统强化学习方法在训练扩散模型时,每一步训练通常都需要完成三个步骤:生成新的图片、计算奖励以及更新模型。由于扩散模型生成图片本身计算成本较高,这种训练方式往往需要大量时间和计算资源。
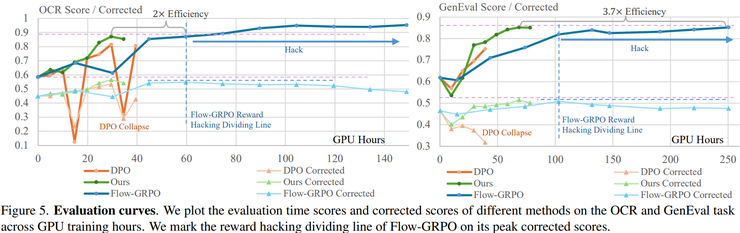
GDRO采用离线训练方式,在训练开始之前先生成数据,然后在训练过程中反复使用这些数据。实验结果显示,在达到相似性能水平时,GDRO所需的训练时间明显更短,并且在某些任务中训练效率可以提升数倍。
方法对比与消融实验
研究人员将GDRO与多种方法进行了对比,包括Flow-GRPO、Dance GRPO以及DPO。这些方法代表不同类型的训练思想,通过在相同实验条件下比较这些方法的效果,可以更加清楚地验证GDRO在性能和稳定性方面的优势。
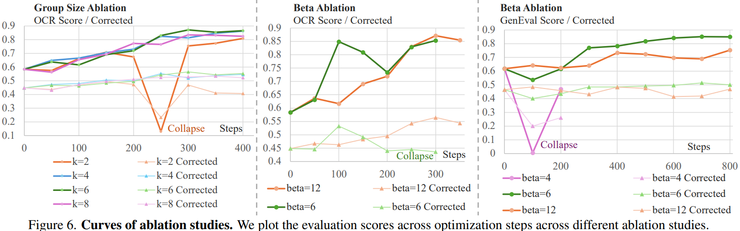
消融实验重点分析了不同参数设置对模型表现的影响。其中一个重要实验是改变图像组大小。当图像组大小只有2时,训练过程会出现明显的不稳定现象;当图像组大小增加到4或6时,训练稳定性明显提高。这是因为组级奖励能够提供更加丰富的排序信息,使模型在训练过程中获得更稳定的优化信号。
技术意义与产业价值
对学术研究的启示
这项研究体现了三个重要结论:首先,扩散模型同样可以进行奖励对齐,但需要针对其结构特点设计专门的优化方法;其次,离线训练能够显著降低训练成本,这对计算资源密集的扩散模型训练尤为重要;最后,评价指标的使用需要保持谨慎,高评分并不一定意味着生成结果质量更高。
工业应用前景
对于工业界而言,GDRO方法具有明显的工程价值。企业可以在不显著增加算力投入的情况下,对大规模扩散模型进行后训练优化。这意味着以更低的计算资源消耗就能提升模型表现,这对需要部署大规模生成模型的企业来说具有重要意义。

未来发展方向
基于GDRO的研究成果,未来可以在以下几个方向继续深入探索:首先,可以进一步优化组级奖励的计算方法,使其能够更准确地反映图像的真实质量;其次,可以探索将GDRO方法应用于其他类型的生成模型;最后,可以研究如何将这种方法与在线训练相结合,在保证训练效率的同时进一步提升模型性能。
这项研究为生成模型的对齐优化提供了新的思路和方法,不仅解决了当前存在的奖励作弊问题,还为后续研究奠定了重要基础。随着技术的不断发展,相信会有更多创新方法出现,推动生成模型在真实场景中的应用。