近期在技术社区引发热议的“同事.Skill”项目,表面上似乎实现了将真实同事“炼化”为数字人格的神奇效果,但当我们深入剖析其技术实现和运作机制,会发现这只是一个相对简单的技术组合。
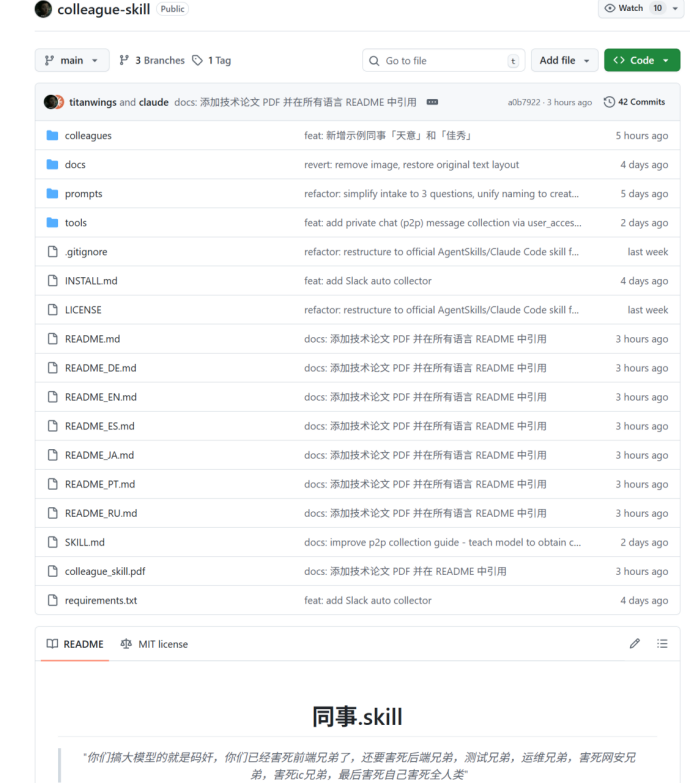
该项目在colleagues文件夹下为每个“数字同事”建立子目录,包含几个核心文件:Skill.md作为主入口,work.md描述工作内容,persona.md定义性格特征,meta.json存放元数据。这种设计本质上是对个人工作特征的文本化封装。
数据收集环节使用Python脚本进行平台数据抓取,包括feishu_auto_collector.py用于飞书消息和文档收集,dingtalk_auto_collector.py处理钉钉数据,wechat_parser.py解析微信聊天记录,email_parser.py处理邮件内容。这些脚本的功能局限于数据格式转换和整理,将原始文本统一处理后喂给AI进行特征总结。
运行机制更为简单:当调用Skill时,AI模型读取静态Markdown文件作为上下文,按照预设风格进行对话。这类似于给演员提供剧本,指示其扮演特定角色,而非真正的思维复制或AI训练。
项目中的“五层人格结构”设计值得关注,但这只是提示词的组织方式。persona.md将人格描述分为五个层次:Layer 0设定硬性规则,Layer 1定义身份认知,Layer 2确定表达风格,Layer 3描述决策模式,Layer 4规定人际行为。这种分层设计虽然系统化,但本质上仍是角色扮演指南。

技术局限性主要体现在几个关键方面。首先是记忆系统的缺失,每次对话都是重新读取静态文件,无法实现持续学习和记忆更新。这种设计导致Skill无法记住之前的对话内容,也无法根据交互反馈调整行为。
其次是数据质量决定输出质量的GIGO原则(垃圾进,垃圾出)。如果原始数据质量较差,如聊天记录中多为简单回复或闲聊内容,生成的Skill效果必然受限。数据源的丰富程度和质量直接影响数字人格的完整性和实用性。
另一个重要问题是人格漂移现象。随着对话轮次增加,初始的人格定义提示词在上下文中的权重逐渐稀释,导致AI逐渐偏离预设角色。这种现象在长时间交互中尤为明显。
更为深层的是“专家悖论”问题。当要求AI扮演专家角色时,模型可能过度关注模仿专家的表达方式和职业习惯,反而影响对问题本身的准确判断。这种角色约束与知识输出之间的平衡需要精细调校。
从能力提取角度看,这类项目能够捕捉的主要是表面特征:口头禅、表达习惯、常用技术栈和显性工作流程。但对于复杂情境下的判断力、创新性问题解决能力和基于经验的直觉等深层能力,现有技术还难以有效提取和复现。
在代码生成方面,Skill确实能够输出符合特定风格的代码片段,但在需要架构决策和创造性解决方案的场景下,其能力明显不足。真正的工程决策需要权衡多重因素,这是当前技术难以完全模拟的。
法律风险分析
该项目涉及的法律风险不容忽视。根据《个人信息保护法》第13条规定,处理个人信息需要满足特定条件,如取得个人同意、为履行合同所必需等。员工离职后,公司继续使用其工作数据创建数字人格,很难符合这些法定条件。
特别需要注意的是敏感个人信息保护问题。工作聊天记录中可能包含个人健康状况、家庭情况、财务信息等敏感内容。《个人信息保护法》第28条明确要求处理敏感个人信息需要取得“单独同意”,而项目现有的操作流程完全忽略了这一要求。
平台服务协议合规性也是重要考量因素。例如微信数据收集可能违反《腾讯微信软件许可及服务协议》,未经许可的数据复制和读取属于违规行为。《数据安全法》第45条更规定了数据安全保护义务,违规可能面临刑事责任。
在实际应用中,如果公司真的使用这种方式“留住”离职员工,将面临多重法律风险。离职员工可以投诉要求删除数据并索赔,公司可能面临行政处罚和民事赔偿,甚至引发集体诉讼。
技术传播与公众认知
这个项目的流行过程反映了技术传播中的典型现象。起源于技术社区的玩梗行为,在传播过程中逐渐被神化和误解。X平台用户最初用“被蒸馏成Token”调侃AI时代的价值衡量方式,但经过多次传播后,简单的技术项目被包装成“数字永生”的象征。
这种传播失真现象的核心在于公众对AI技术的认知空白。大多数人不了解提示词工程与模型训练的区别,不清楚上下文注入与真实记忆的差异,也无法区分角色扮演和人格复制。这种认知差距为夸大叙事提供了生存空间。
媒体在传播过程中的角色值得反思。为了吸引流量而夸大技术能力,虽然短期内能够获得关注,但长期来看会误导公众对AI技术的理解,加剧不必要的焦虑情绪。
数据质量决定效果
项目的README文件明确指出“原材料质量决定Skill质量”,这反映了AI应用中的基本规律。数据质量直接影响输出效果,在数字人格创建过程中尤为明显。
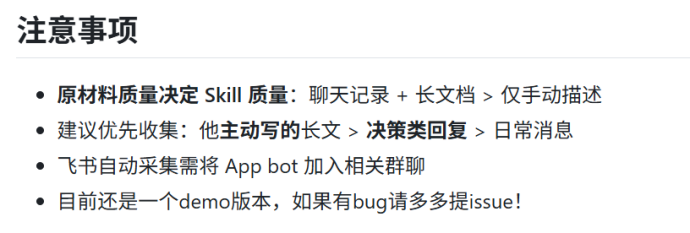
高质量的数字人格需要丰富、准确、有代表性的数据支持。如果数据源局限于工作场景的格式化交流,生成的数字人格往往缺乏深度和个性。真正的个人特质、思维方式和决策逻辑很难通过有限的工作数据完全捕捉。
技术发展的合理定位
尽管存在诸多限制,这类项目在知识传承和工作辅助方面仍有其价值。作为带人设的聊天机器人或智能化工作日志,它可以成为团队知识管理的辅助工具。但在定位时需要保持理性,避免过度夸大其实际能力。
从技术发展角度看,这类项目展示了结构化封装“人格”的可能性,为未来更成熟的数字人格技术提供了探索方向。但在当前阶段,技术成熟度还远未达到替代真实人类的程度。
个人数据权利保护
这个案例凸显了AI时代个人数据权利保护的重要性。随着AI技术日益普及,如何在技术创新与个人权利保护之间找到平衡点成为关键问题。
现有的法律法规框架需要进一步完善,以适应AI技术带来的新挑战。企业需要建立更严格的数据使用规范,确保在技术创新过程中充分尊重个人数据权利。
个人也需要提高数据保护意识,了解自己在数字时代的权利边界。在享受技术便利的同时,保持对个人数据的控制权和知情权。
行业影响与未来展望
这个项目的流行反映了当前AI技术应用的某些趋势。一方面,技术门槛的降低使得更多人可以参与AI应用开发;另一方面,技术理解的浅层化可能导致应用场景的误判。
未来,随着技术不断发展,数字人格技术可能会走向更成熟的方向。但在发展过程中,需要建立完善的技术标准、伦理规范和法律框架,确保技术创新服务于人类福祉。
对于职场应用而言,AI技术应该定位于辅助和增强人类能力,而非完全替代。合理的技术应用可以提升工作效率,但需要避免技术滥用带来的伦理和法律问题。
这个案例提醒我们,在拥抱技术创新的同时,需要保持理性判断,避免被技术噱头所迷惑。真正的技术进步应该建立在扎实的技术基础和合理的应用场景之上。