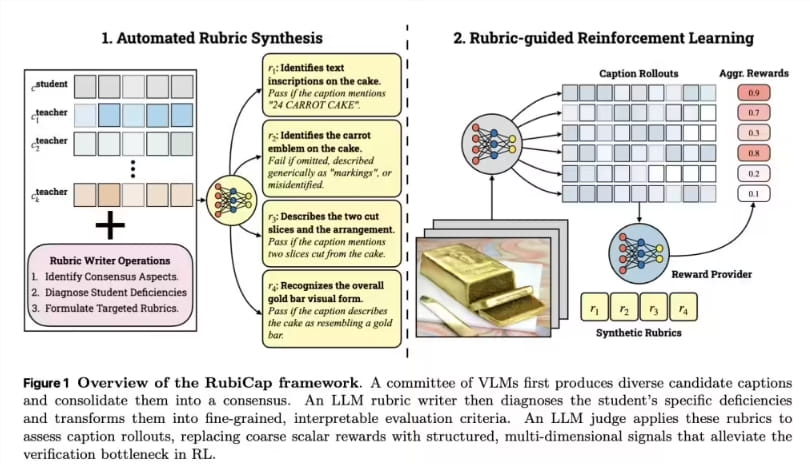
在机器人技术的发展历程中,我们经常观察到这样的场景:机器人伸手去拿桌上的杯子,刚把杯子抬起来又停住,随后放回原位,然后再次伸手去拿。同一个动作重复执行,仿佛机器人忘记了自己刚刚完成的操作。类似的情况在真实环境中并不少见——按钮明明已经按下却还在反复按压,抽屉已经关好却仍在继续推动。
这些失败案例并非源于机器人“看不清”环境,而是因为它们缺乏一套能够模拟时空演化的“世界模型”。当前的视觉语言动作模型虽然能够理解图像与指令,但在连续任务中仍然只能依赖当前观测做决策。一旦任务变成长步骤流程,例如拿起物体、移动、放置再到关闭装置,就容易出现动作重复和决策中断的问题。
时间认知:机器人智能的关键瓶颈
现有的大多数方法基于“看到什么就做什么”的即时反应机制,在短任务中表现良好,但在长序列任务中容易出现动作不连贯和决策漂移。这种局限性正在成为具身智能发展的关键瓶颈。
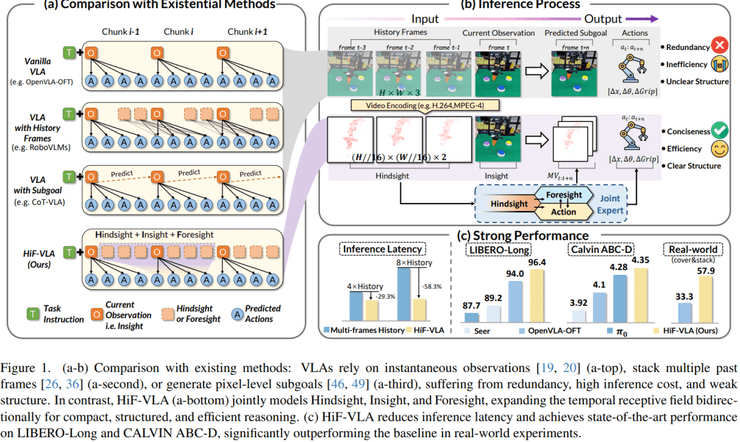
传统模型在处理时间维度信息时存在明显不足。它们要么完全忽略历史信息,要么通过堆叠历史图像来引入时间维度,但这种方式存在信息冗余严重以及计算成本较高的问题。另一种方法是通过预测未来图像作为子目标来引导决策,但容易产生误差且稳定性较差。
HiF-VLA:基于运动信息的时间建模创新
针对这一挑战,研究人员提出了一种全新的方法:以“运动”作为时间信息的核心表达。这种方法不再简单依赖历史图像或未来画面预测,而是通过运动信息使模型能够同时建模过去的变化、当前状态以及未来趋势。
运动信息相比图像更适合用于表示时间变化,因为图像中包含大量静态信息,而运动信息只保留了真正发生变化的部分,因此更加高效且更具表达力。这种创新使得机器人从“被动反应”走向“边思考边行动”成为可能。
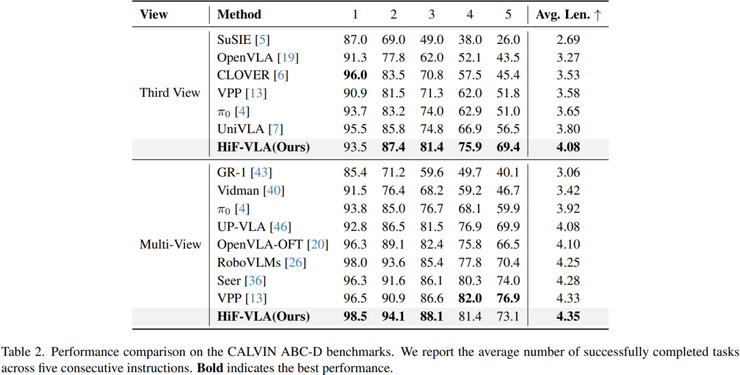
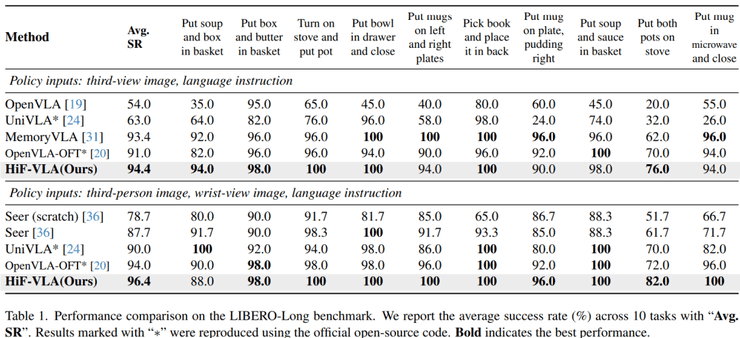
在LIBERO-Long长序列任务上的测试结果显示,HiF-VLA在单视角条件下的成功率达到94.4%,在多视角条件下达到96.4%。作为对比,当前较强的方法OpenVLA-OFT在单视角下为91.0%,多视角为94.0%。这意味着该方法在单视角下提升了3.4个百分点,在多视角下提升了2.4个百分点。
跨环境泛化能力的显著提升
在CALVIN跨环境泛化任务中,研究在A、B、C三个环境中训练模型,并在未见过的D环境中进行测试。评价指标是连续成功完成任务的数量,即在不中断的情况下能够连续完成多少个步骤。
结果显示,HiF-VLA在单视角下达到4.08,在多视角下达到4.35,而传统方法OpenVLA-OFT约为4.10,Seer约为4.28,RoboVLMs约为4.25。这个提升具有重要意义,因为该指标一旦中间某一步失败后续任务将不再计入,因此数值越高说明模型在长时间连续决策中的稳定性越强。
计算效率与性能的平衡
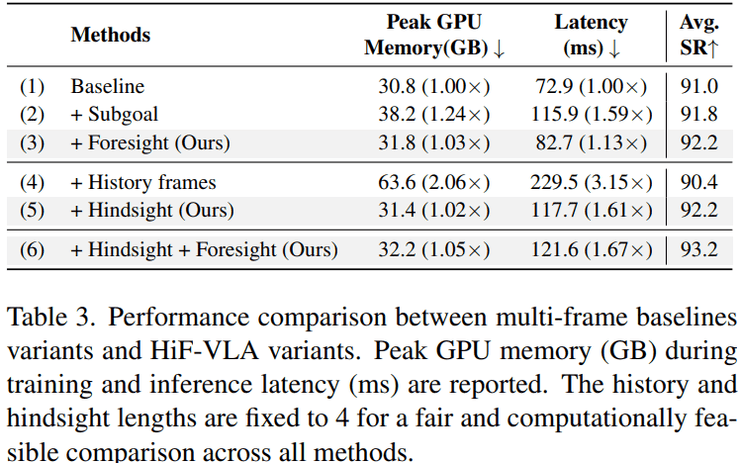
在效率与计算成本方面,研究进一步分析了性能提升是否以计算开销为代价。结果显示,当引入基于图像的未来子目标预测时,成功率为91.8%,但延迟增加到115.9毫秒,比基线慢1.59倍。当采用历史帧堆叠时,成功率反而下降到90.4%,延迟上升到229.5毫秒,是基线的3.15倍。
相比之下,HiF-VLA在只加入未来推理时,成功率为92.2%,延迟为82.7毫秒,几乎没有额外开销;只加入历史信息时,成功率同样为92.2%,延迟为117.7毫秒;同时加入两者后,成功率达到93.2%,延迟为121.6毫秒。整体来看,该方法在提升成功率的同时,计算成本远低于堆叠历史帧的方法。
时序长度扩展能力的优化
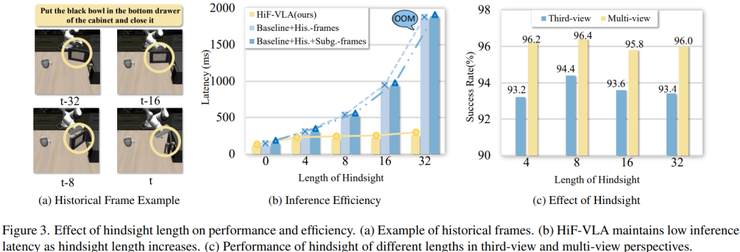
在时序长度扩展能力方面,研究逐步增加历史长度,从4到8,再到16和32。结果表明,当长度为8时性能最佳,单视角为94.4%,多视角为96.4%,继续增加长度反而会导致性能下降,其原因在于信息过多带来的冗余干扰。
在延迟方面,传统方法的计算成本会随着历史长度线性增长,当长度为8时延迟增加约4.5倍,而HiF-VLA的延迟基本保持稳定,仅有轻微增长,说明其在时间维度上具有更好的扩展性。
真实环境中的验证
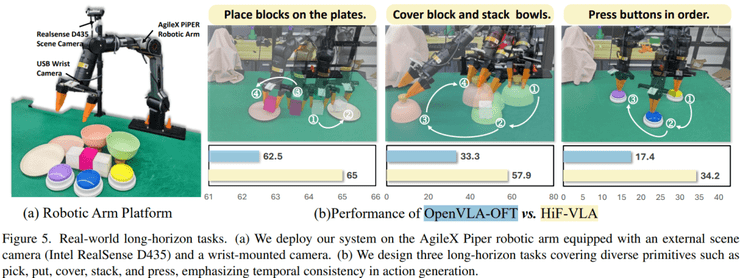
在真实机器人实验中,研究设置了多个长序列任务来验证实际效果。在按顺序按按钮任务中,基线方法的成功率为17.4%,而HiF-VLA提升到34.2%,接近翻倍。在覆盖与堆叠任务中,基线为33.3%,该方法达到57.9%,提升了24.6个百分点。
在放置任务中,基线约为62.5%,该方法约为65%,提升较小但表现更加稳定。研究人员分析认为,基线方法难以判断按钮是否已经被按下,因为状态变化较为细微,而HiF-VLA能够利用时间变化信息来识别状态转变,因此在复杂任务中表现更好。
系统性的方法对比
在实验设计方面,研究团队设置了多种不同方法进行系统比较。第一种方法仅使用当前观测信息进行决策,不包含任何时间信息。第二种方法通过堆叠历史图像来引入时间信息,但存在信息冗余问题。第三种方法通过预测未来图像作为子目标来引导决策,但稳定性较差。
相比之下,HiF-VLA采用运动信息替代图像来表示时间变化,从而减少冗余信息并提高建模效率。在输入信息设计方面,模型同时接收三类信息:当前画面作为对当前状态的感知信息,历史运动作为对过去动态变化的表达,以及语言指令用于提供任务目标。
消融实验的深入分析
在消融实验中,研究进一步分析了不同设计选择对性能的影响。首先在历史长度方面进行实验,结果表明最优长度为8,当长度过短时无法提供足够的信息,而长度过长则会引入冗余并影响模型判断。
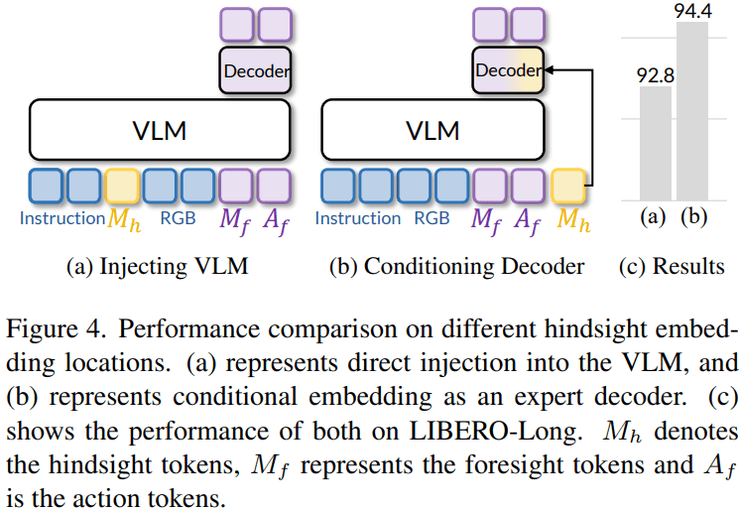
其次在历史信息的使用方式上,研究比较了两种策略:一种是将历史信息直接输入视觉语言模型,此时成功率为92.8%;另一种是将历史信息注入到决策模块中,此时成功率提升到94.4%。这一结果说明,将历史信息直接加入视觉语言模型会影响其原有的视觉与语言理解过程,而在决策阶段引入历史信息能够更有效地发挥其作用。
从技术突破到范式转变
这项研究的意义不仅在于技术性能的提升,更在于推动了一种新的智能范式。从“看到就做”的视觉语言行动模型到“边想边做”的世界行动模型,HiF-VLA改变的不仅是模型的结构设计,更是在重新定义机器人应当具备的能力边界。
过去的系统更像是被动反应的执行者,只对当前输入做出即时回应;而在这种新的范式下,机器人开始具备连续决策的能力,能够在行动中记住刚刚发生了什么,判断当前处于什么阶段,并预判接下来应该做什么。
实际应用前景与挑战
这种变化的意义在于,机器人不再只是完成单步动作,而是能够理解一整段过程,并在过程中不断调整自己的行为。这也意味着,具身智能的发展正在从“感知驱动的反应系统”走向“时间驱动的推理系统”。
当模型真正具备这种能力时,机器人才能在复杂、动态的真实环境中稳定工作,而不仅仅是在受控场景中完成预设任务。这在工业自动化、家庭服务、医疗护理等领域具有广泛的应用前景。
然而,这项技术仍然面临一些挑战。首先是运动信息的提取精度问题,在复杂环境中准确提取有意义的运动信息仍然存在难度。其次是模型对不同类型的运动模式的适应性,不同任务可能需要不同的时间建模策略。
未来发展方向
基于当前的研究成果,未来有几个重要的发展方向值得关注。首先是运动信息提取技术的进一步优化,如何在不同场景下提取更具代表性的运动特征是一个关键问题。
其次是模型架构的改进,当前的方法虽然有效,但可能不是最优的解决方案。探索更高效的时间建模架构将有助于进一步提升性能。
最后是应用场景的拓展,将这种方法应用于更复杂的真实世界任务,验证其在各种环境下的鲁棒性和适应性。
技术影响的深远意义
HiF-VLA的研究成果对机器人技术发展具有深远影响。它不仅解决了一个具体的技术问题,更重要的是为整个领域指明了一个新的发展方向——让机器人具备时间认知能力。
这种能力的获得将使机器人能够更好地理解世界的动态变化,从而在真实环境中做出更加智能和合理的决策。从长远来看,这可能是实现真正通用人工智能的重要一步。
随着技术的不断成熟和完善,我们有理由相信,具备时间认知能力的机器人将在不久的将来在各个领域发挥重要作用,为人类社会带来实质性的变革。