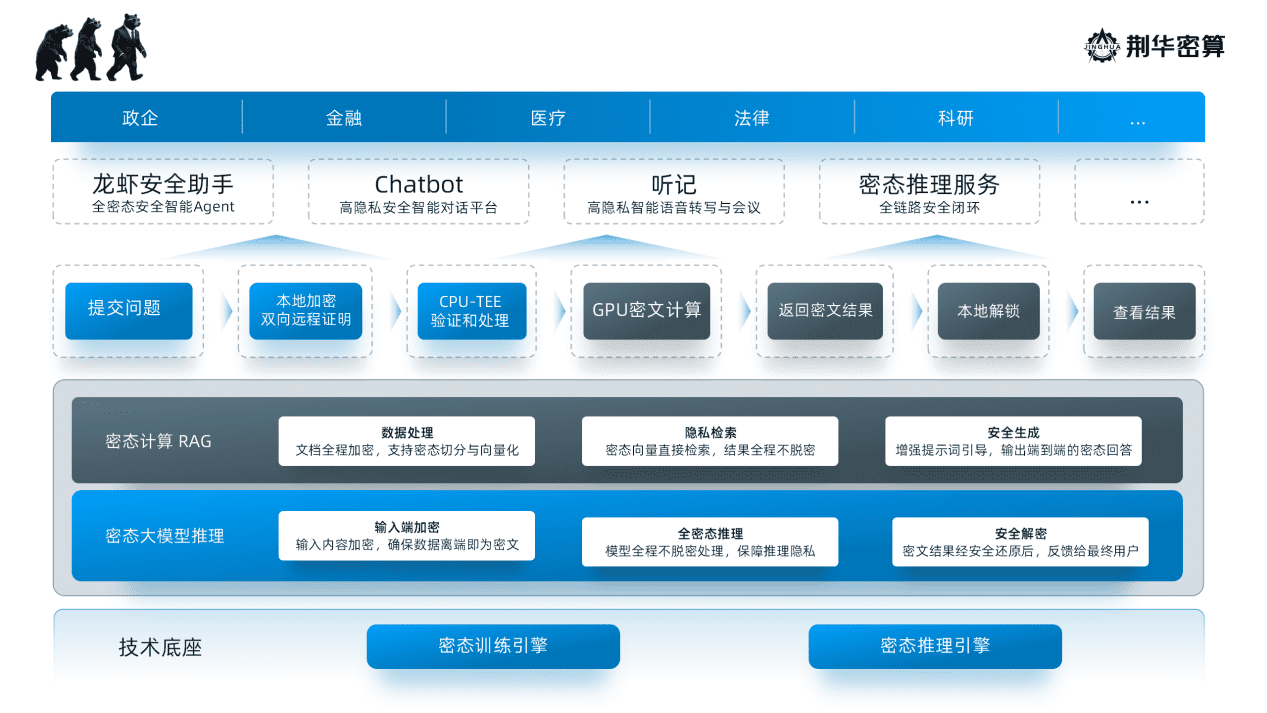
设计初衷与使用场景的严重脱节
OpenClaw(俗称"龙虾")近期从备受推崇跌落到争议漩涡,核心问题并非模型智能度不足或代码缺陷,而是其设计理念与实际应用场景产生了根本性错配。这款工具的创新功能——从心跳保活到全屏信息识别——本质上都是为专业开发者调试需求而打造,当这些功能突破原有使用边界进入普通用户手中时,必然引发性能冗余和逻辑紊乱。

心跳保活机制:稳定性的代价
心跳保活机制作为OpenClaw的核心功能之一,其设计初衷是通过定时数据同步确保AI能够实时掌握电脑状态。这一机制主要解决两个关键问题:环境对齐和长任务稳定性保障。
在开发场景中,环境对齐至关重要。通过定期同步屏幕内容和剪贴板信息,大模型能够保持对计算机当前状态的持续认知,确保接收到指令后能够无缝衔接执行,避免出现状态断层。对于数据爬取、跨表格生成等耗时数小时的长周期任务,心跳机制能够有效防止因网络波动或模型超时导致的任務中断,其原理类似于文件传输的断点续传功能。
然而,这一面向开发者的创新设计在普通用户场景下却成为Token消耗的主要黑洞。问题的根源在于Transformer架构的无状态特性——模型每次API调用都需要完整的上下文信息才能正常运行。每次心跳校验都需要上传屏幕OCR结果、会话摘要等全量数据,导致闲置状态下的开销甚至超过实际工作时的消耗。
更值得注意的是,为了避免AI角色设定出现偏差,每次上下文打包除了实时屏幕画面和对话信息外,还必须包含AGENT.md和SOUL.md中数千字的固定配置文件。这种设计相当于每次分配任务前都要求员工重温公司章程,高频的系统提示词"税收"直接推动了Token消耗的急剧上升。
针对心跳机制的优化策略包括两个主要方向:一是调整心跳频率,将默认间隔延长至数小时,在无任务时段完全关闭心跳功能;二是实施分层运行方案,使用本地小型模型处理常规心跳任务,仅在遇到复杂推理需求时调用云端大型模型。
业界正在探索的更高效解决方案包括上下文缓存技术和事件驱动模式。上下文缓存通过在云端API将系统提示词和历史对话标记为固定前缀生成缓存,后续心跳只需传输增量信息,可显著降低消耗。然而,现有缓存存活时间通常仅5-10分钟,若要充分利用缓存优势反而需要提高心跳频率,形成新的成本矛盾。
事件驱动模式则更为彻底,将按时轮询改为特定事件触发。主流实现思路包括将屏幕监控任务交由操作系统处理,仅在特定事件(如微信弹窗)发生时唤醒模型,但这需要完善的生态系统支持和严格的隐私保护措施。视觉差分拦截采用SSIM等低算力算法预先比对屏幕变化,在画面无变动时取消请求,实现零Token消耗,操作门槛相对较低。
单模型配置:资源分配的失衡
OpenClaw的第二个Token黑洞源于其单模型全场景配置策略。默认使用同一大型模型处理所有类型请求,导致资源分配严重失衡。
选择包月套餐的用户往往会发现,AI供应商为控制成本提供的多是10B参数以下的小型模型,这些模型在执行任务时智能水平明显下降,需要用户持续进行纠错指导。原本期望通过AI提升效率,结果反而成为AI的"保姆"。
而选择高价接入深度思考模型的用户则面临另一种困境:这些高端模型专长于复杂逻辑推理、长流程规划和异常处理等高难度工作,但在实际应用中却要承担大量常规调度和固定流程触发等机械性操作。考虑到OpenClaw已内置像素级键鼠控制和窗口管理能力,模型只需输出标准化指令即可。使用顶级模型执行此类基础操作不仅是大材小用,还会产生两个负面效应。
首先,执行准确率不升反降。高端深度模型具有更长的思维链和更强的发散性,面对简单机械操作时容易过度推理。加上普通用户通常不会设置场景化硬约束,导致本应简单的操作反复出错。
其次,Token消耗急剧增加。深度模型处理简单操作时会产生大量不必要的推理和说明内容,这些内容不仅浪费Token资源,还会占满上下文窗口,拖慢任务执行速度。

优化这一问题的关键在于实施算力分层策略,让合适的模型处理合适的任务。机械执行类工作应交由10B参数以内的轻量化专用模型处理,例如Qwen2-VL-7B等多模态模型,这些模型仅需5-6GB显存,推理速度快且服从性高。只有在需要复杂思考的场景下才调用昂贵的深度思考模型,实现资源的最优配置。
这种大小模型协同的优化思路已被微软AutoGen、阿里通义AgentScope、百度智能云AgentBuilder等主流AI智能体框架采纳,成为行业公认的降本增效方向。
全屏扫描:精准与效率的权衡
OpenClaw凭借其强大的端侧计算机视觉能力在AI智能体领域中脱颖而出,但无差别的全屏扫描也成为第三个重要的Token消耗点。
通过全屏扫描与OCR识别技术,OpenClaw能够像人类一样监控屏幕操作,精准定位操作按钮并自动控制键鼠,甚至能够强制接管未开放API的本地软件。这一能力是其核心竞争优势,但也构成了Token消耗的重要来源。
由于默认采用全量屏幕扫描策略,系统无法区分有效信息与冗余内容。即使是简单的"打开浏览器"指令,屏幕边缘的广告和桌面壁纸等无关元素都会被识别并传输给模型处理。
更为严峻的是,大模型的图像计费逻辑与文本处理完全不同,其Token消耗与屏幕分辨率直接相关。在ViT架构的底层逻辑中,模型无法像人眼那样一次性处理整张图像,必须将高清截图分割成512×512像素的区块进行逐个运算。对于4K或超宽屏幕,即使截图中仅有一个确认按钮,也会被分解成数十个区块,大量计算资源浪费在无效像素处理上,单次Token消耗可达数千。
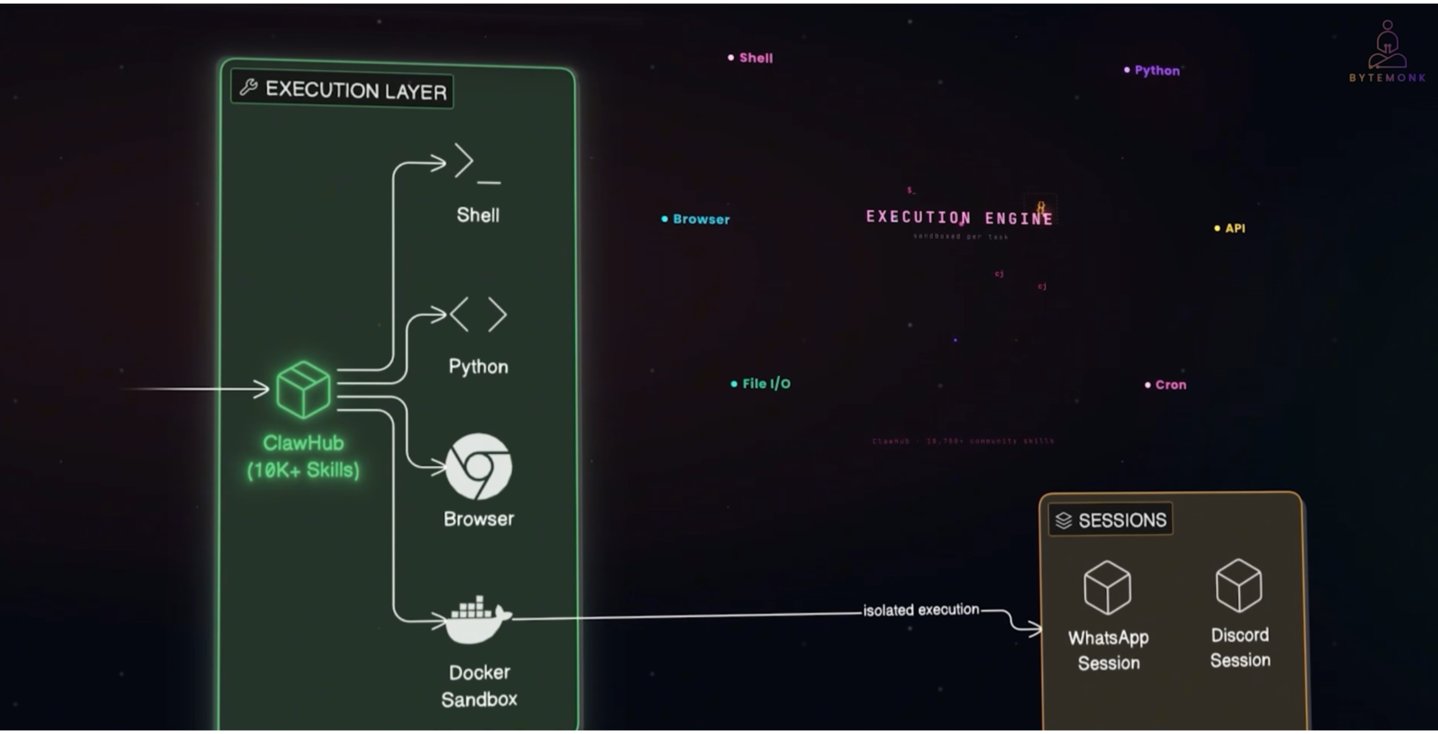
目前针对这一问题的解决方案仍在探索中。部分开发者选择激活窗口聚焦功能,仅扫描当前操作窗口;另一些则在研发非交互元素过滤技术,只识别可操作控件。Anthropic采用的Computer Use计算机控制技术通过"像素计数"设计,将电脑屏幕映射为二维坐标网格,识别后直接返回精准操作坐标,无需额外视觉定位步骤,交互逻辑更接近人类操作模式。
技术适配与用户体验的平衡
综合分析OpenClaw的三大Token消耗点,可以清晰看到技术设计与使用场景之间的严重错配。这些在开发者眼中极具价值的功能创新,在普通用户场景下却成为成本负担。
技术的价值不在于其先进性,而在于与使用场景的匹配程度。OpenClaw作为一款优秀的开发者工具,其问题核心并非技术缺陷,而是目标用户群体的错位。要真正解决上述问题,用户需要具备一定的技术背景,能够进行持续优化和调整。
对于寻求即用型解决方案的用户,业界各大厂商提供的智能体框架可能更为合适。这些产品通常经过更全面的用户体验优化,在成本控制和易用性方面表现更为均衡。
随着AI技术的不断发展,智能体工具的设计理念正在从纯技术导向转向用户体验导向。未来的优化方向将更加注重场景化适配和资源效率平衡,推动AI工具向更普惠、更易用的方向发展。