重新定义注意力机制:从序列处理到深度维度的跨越
在人工智能领域,注意力机制的革命性突破往往带来架构层面的重大变革。最近Kimi团队提出的Attention Residuals技术,正是这样一个具有里程碑意义的创新。这项技术巧妙地实现了注意力机制从序列处理维度向深度维度的转移,为解决大模型训练中的核心问题提供了全新思路。
传统残差连接的局限性
要理解这项创新的价值,我们首先需要审视传统残差连接的工作原理。在标准的PreNorm范式中,第N层的输出等于该层计算结果与前一层输出的简单相加。这种设计虽然保证了梯度流动,但也带来了明显的问题。
所有层的贡献都以相同权重累加,就像一个人把所有经历都以相同重要性存入记忆。早期信息在层层传递过程中被逐步稀释,导致模型难以有效检索底层特征。研究人员将这种现象称为"PreNorm稀释问题"。
更严重的是,隐藏状态的范数会随着网络深度不断增长。在深层网络中,这种无限制的增长往往导致训练过程的不稳定性,限制了模型的深度扩展能力。
注意力机制的新应用场景
Kimi团队的突破在于发现了一个关键的对偶性:网络深度维度与序列时间维度在本质上具有相似性。既然Transformer在处理序列时能让当前位置选择性关注之前的位置,那么在深度维度上,为什么不能让当前层选择性关注之前的层?
这种洞察催生了Attention Residuals技术。其核心思想是:
- 使用当前层的可学习伪查询向量作为query
- 将所有前层的输出作为key和value
- 通过注意力机制进行加权聚合
这种方法让网络学会自主判断哪些层的信息对当前计算最为重要,从而实现有选择性的信息提取。不相关的层权重会自动降低,避免了传统残差连接中的信息稀释问题。
工程实现的技术挑战与解决方案
然而,这种设计带来了显著的计算复杂度问题。对于一个100层的网络,如果每一层都需要对前面所有层进行全注意力计算,复杂度将达到O(L²),这在实践中是不可行的。
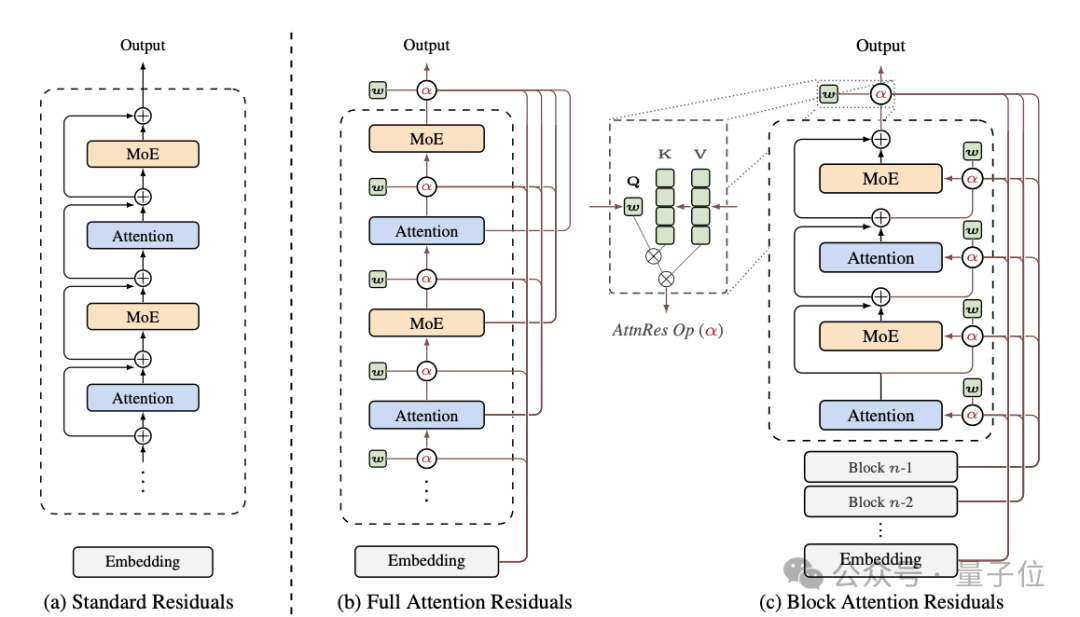
团队通过Block AttnRes方案解决了这一挑战。该方案将连续的层分组为block,在每个block结束时将内部信息压缩为单个摘要向量。这样,后续层只需要关注块间表征和块内实时层输出,而非全部层的信息。
具体实现中,团队将L层网络划分为B个block,每个block包含若干层。通过这种分组策略,注意力复杂度从O(L²)降低到O(L·B)。在实践中,B可以设置为较小的值(如8-16),在保证性能的同时大幅降低计算负担。
除了核心算法优化,团队还实施了一系列工程改进措施,包括缓存式流水线通信、序列分片预填充、KV缓存粒度优化等,确保技术在实际部署中的可行性。
大规模验证与实际效果
理论创新必须经过实践检验。团队在Kimi Linear架构上进行了全面测试,这是一个采用线性注意力的大模型,总参数480亿,激活参数30亿(采用MoE架构)。
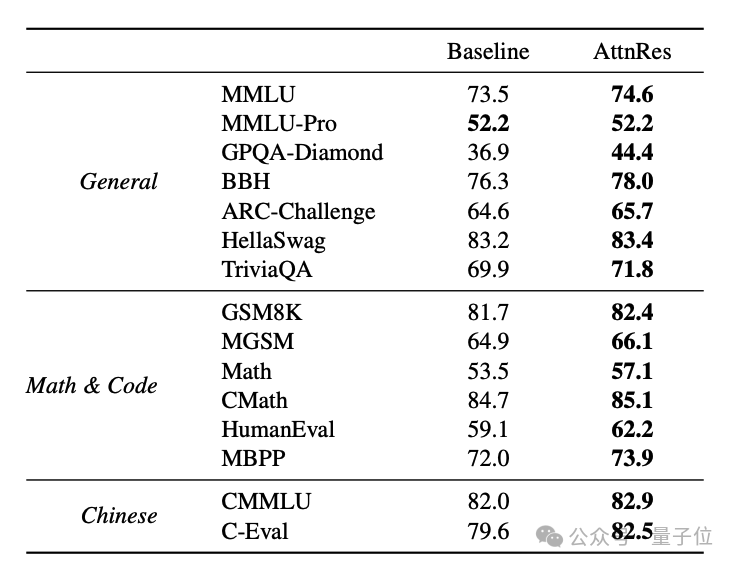
测试结果显示,在同等计算预算下,Attention Residuals能够获得更好的下游性能。反向验证表明,达到相同性能水平所需的训练计算量减少了约20%,相当于获得了1.25倍的效率优势。
在具体任务表现上,数学推理(MATH、GSM8K数据集)和代码生成(HumanEval、MBPP数据集)任务均实现持平或略微提升,多语言理解的一致性也有所改善。最重要的是,Attention Residuals可以作为即插即用的替代方案,无需修改网络其他部分,直接替换传统残差连接即可。
时间-深度对偶性的理论意义
这项工作的理论贡献在于提出了"时间-深度对偶性"概念。团队认为,深度神经网络的"层"与循环神经网络的"时间步"本质上都是对信息的迭代处理。
Transformer的成功在于用注意力机制替代了RNN中固定的循环结构。那么在深度维度上,同样应该用注意力机制替代固定的残差连接。这种对称性思考为神经网络架构设计提供了新的理论框架。
年轻研究者的成长轨迹
这项研究的另一个亮点是团队组成的多样性。共同一作之一的陈广宇年仅17岁,他的加入为这项前沿研究注入了新鲜视角。
陈广宇的成长轨迹体现了当代技术人才培养的新模式。从北京的一场黑客松开始,他展示了关于"人类第三只机械辅助手"的创新构想,这个项目让他结识了创业导师董科含。在导师的建议下,他从经营电商店铺转向深入理解底层技术。
通过研读经典论文、追踪GitHub开源项目,陈广宇逐步建立起对AI技术的系统认知。他在社交媒体上的技术分享引起了硅谷AI初创公司的关注,最终获得了实习机会。在硅谷期间,他参与了涉及144张H100显卡的大型项目,积累了宝贵的实践经验。

回归国内后,陈广宇加入月之暗面,专注于Flash Linear Attention等高效注意力工作。正是GitHub上的FLA项目最初激发了他对机器学习的兴趣,这种兴趣最终引导他参与到最核心的大模型研发工作中。
技术前景与行业影响
Attention Residuals技术的出现预示着大模型架构设计的新方向。传统残差连接虽然简单有效,但在超大规模模型场景下显露出明显局限性。基于注意力的残差连接为解决深层网络训练问题提供了更优雅的解决方案。
这项技术的成功验证表明,注意力机制的应用边界远未达到极限。从序列处理到深度维度,再到未来可能探索的其他维度,注意力机制有望成为连接不同神经网络组件的通用桥梁。
对于行业而言,这种创新带来的效率提升具有实际意义。训练计算量减少20%意味着在相同硬件投入下可以获得更好的模型性能,或者在达到相同性能水平时显著降低计算成本。这对于推动AI技术的大规模应用具有重要价值。
未来发展方向
基于当前成果,该技术有几个值得关注的发展方向:
首先是扩展到更大规模的模型验证。虽然在480亿参数模型上取得了积极结果,但在千亿级甚至更大规模模型上的表现仍需进一步验证。
其次是与其他优化技术的结合。Attention Residuals可以与模型压缩、知识蒸馏等技术结合,形成更完整的效率优化方案。
最后是理论研究的深入。时间-深度对偶性概念的提出为神经网络理论发展提供了新视角,未来可能会有更多基于这一理念的架构创新。
这项研究不仅展示了技术创新,更体现了科研协作的新模式。年轻研究者的参与、开源社区的互动、跨地域的合作,这些因素共同促成了这一突破性成果的产生。
随着AI技术的不断发展,我们期待看到更多像Attention Residuals这样的创新,推动整个领域向更高效、更智能的方向迈进。