研究背景与核心问题
近年来,随着大语言模型规模的不断扩大和预训练强度的持续提升,强化学习在后训练阶段扮演的角色引发了广泛讨论。一方面,强化学习被认为是提升模型推理能力和多步决策表现的关键技术;另一方面,越来越多的实证研究表明,在许多任务上,强化学习带来的性能提升往往难以与"新能力的形成"直接等同。
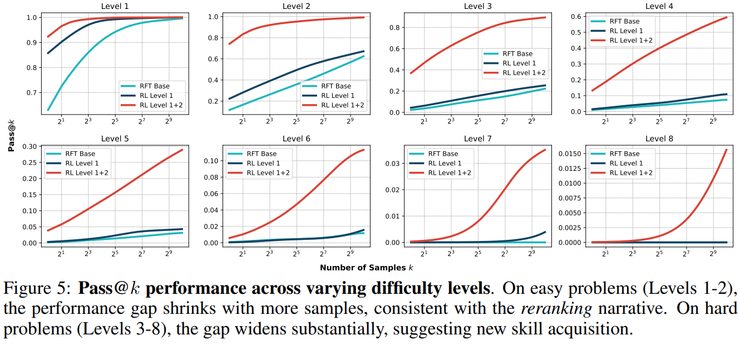
特别是在pass@k等评测指标下,强化学习模型与基础模型之间的差距常常随着采样数的增加而迅速缩小,这使得一种观点逐渐流行:强化学习可能更多是在对模型内部已有解法进行筛选和重排,而非真正拓展模型的能力边界。
然而,这一判断本身面临着验证难题。在自然语言任务中,技能边界高度交织,模型在预训练阶段接触的数据分布几乎无法完全排除,使得性能变化很难被明确归因于能力结构的实质性改变。

实验设计与方法创新
为了突破这一研究瓶颈,清华团队选择退回到一个更可控的实验环境,转而聚焦一个更基础的根本性问题:强化学习究竟能否教会模型此前并不具备的新能力?
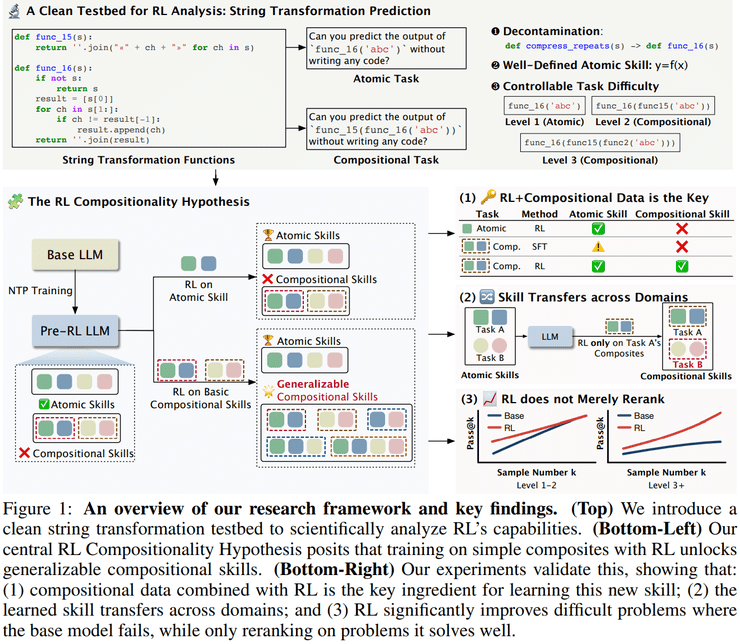
研究团队设计了20余个"非常规"字符串操作函数,将"函数结果预测"作为核心任务。为了彻底排除预训练语料污染及模型语义联想的影响,所有函数均采用随机命名的无意义字符串。
实验的核心在于对比两种关键能力:原子能力和组合能力。原子能力指模型在不依赖Prompt中函数定义的前提下,准确预测单一函数f(x)输出的能力;组合能力则指模型预测多层复合函数(如f(g(x)))执行结果的能力。
两阶段训练策略
研究采用了精心设计的两阶段训练流程。在第一阶段,研究人员通过监督学习让模型充分掌握每个字符串变换函数的原子能力。这一阶段仅进行一次,目的是建立稳定的技能基础。
在第二阶段,团队完全隐藏函数定义,仅向模型提供函数名称和输入字符串,迫使模型要么真正理解并组合已掌握的原子技能,要么在任务中失败。这一设置确保了任何性能提升都必须来自于模型内部能力结构的实质性变化。
关键发现与突破
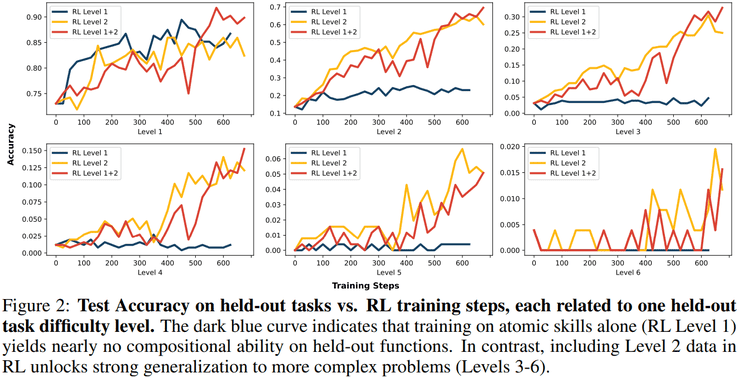
实验结果表明,在合适的激励条件下,强化学习能够使大语言模型获得真正的新能力。这种新能力具体表现为一种系统性的技能组合策略,即模型能够将已经掌握的原子技能按照结构化方式进行组合,并将这一组合策略泛化到更高难度的问题中。
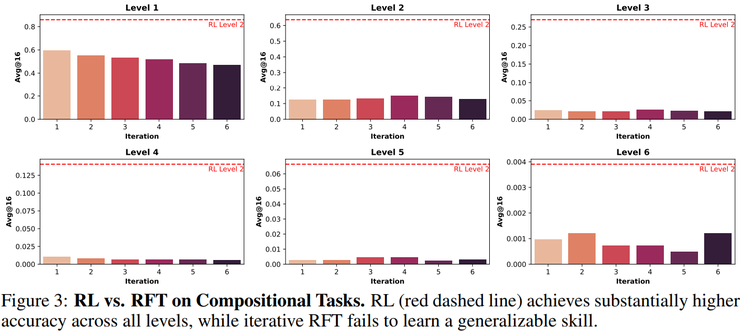
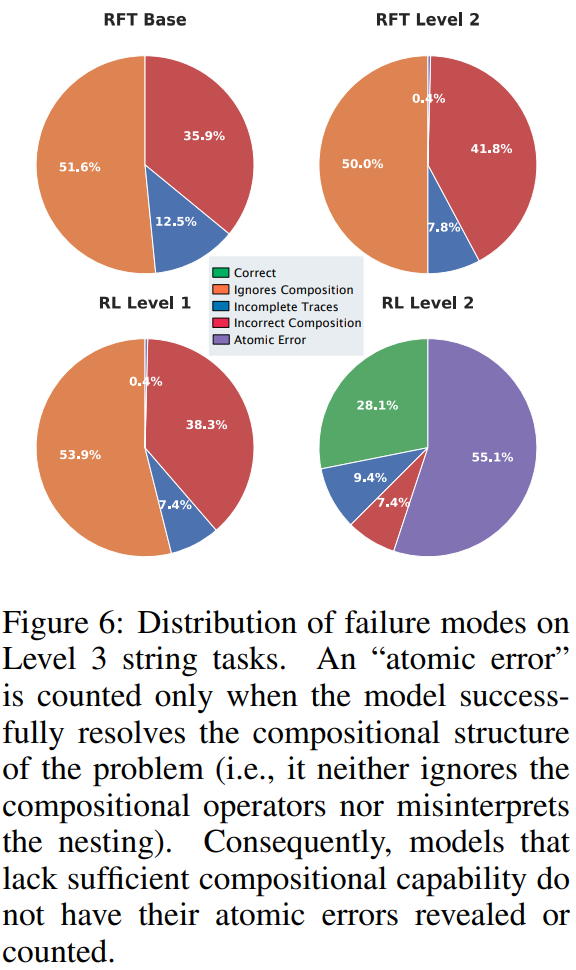
研究人员发现,仅在单函数上进行强化学习的模型,在三层及以上组合任务上的准确率几乎为零。而一旦训练数据中包含最基础的二层嵌套函数,模型在三层组合上的准确率可提升至约30%,在四层组合上仍保持约15%,并在更高层级上持续显著优于随机水平。
跨任务迁移验证
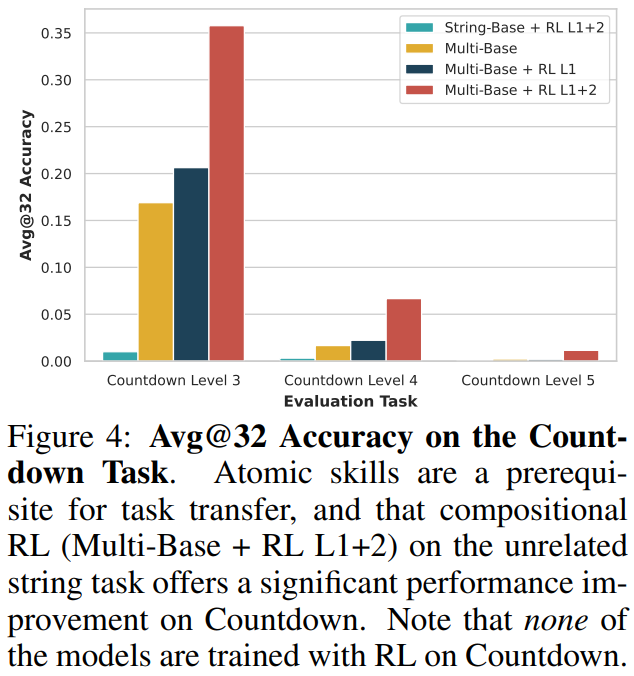
为了进一步验证这种能力的通用性,研究团队进行了跨任务实验。结果显示,如果模型在A、B任务上学习了原子能力,仅在A任务上进行合适的组合能力强化学习,模型就能将该能力泛化至B任务上。
这一发现表明,强化学习获得的并非特定于某一任务的技巧,而是一种能够组织和调度已有原子技能的通用能力,即一种元技能。这种元技能使得模型能够在不同任务间实现能力的有效迁移。
理论意义与实践价值
这项研究的意义远不止于在字符串任务上取得的具体实验结果,更重要的是其对当前大语言模型强化学习研究中的核心争论给出了实质性回应。
研究团队并未给出简单的肯定或否定答案,而是提出了一个条件化结论:强化学习确实能够促使模型获得新的能力,但前提在于模型已经具备完成任务所需的原子技能,同时训练任务的设计能够真实地激励模型去使用并发展这种新能力。
这一结论为大语言模型的训练流程提供了一种启发性的技能分工范式。研究人员隐含地提出,预训练或监督微调阶段的核心作用在于帮助模型掌握基本操作和原子能力,而强化学习更适合用于学习如何组织和调度这些已有能力,从而形成更高层次的推理和决策结构。
研究方法论的创新
这项研究在方法论上的创新同样值得关注。通过使用字符串变换函数作为研究载体,团队成功创建了一个行为完全确定、复杂度可严格控制的环境,有效排除了自然语言任务中固有的模糊性和预训练污染问题。
在这种高度可控的环境下,研究人员能够对"技能"给出清晰而可操作的定义。原子技能被定义为在给定输入的情况下,模型能够正确预测单个函数作用后的输出,而组合技能则指模型在面对嵌套函数时,能够正确推断多个函数顺序作用后的最终结果。
技能难度由函数嵌套的深度直接刻画,这使得"新技能"不再是抽象或主观的概念,而成为可以被精确检验和逐层分析的研究对象。
对未来研究的启示
这项研究为理解大语言模型能力形成机制提供了新的视角。它表明,模型在不同任务之间表现提升的根本原因可能并非知识层面的直接迁移,而是技能结构层面的迁移。即模型学会了一种更通用的能力组织方式,从而能够在新的任务中更有效地利用已有的原子技能。

这一视角为理解多种先进大语言模型在不同领域中展现出的泛化能力提供了重要的分析框架。同时,研究结果也提示我们,在设计和评估大模型训练策略时,需要更加关注能力结构的实质性变化,而非仅仅依赖表面性能指标。
结语
清华大学刘知远团队的这项研究,通过严谨的实验设计和创新的研究方法,为强化学习在大语言模型能力培养中的作用提供了有力的证据。研究不仅证实了强化学习在特定条件下能够教会模型真正的新能力,更重要的是建立了一套可复制、可验证的研究范式,为未来相关领域的深入研究奠定了基础。

随着人工智能技术的不断发展,对模型能力形成机制的深入理解将变得越来越重要。这项研究在这一方向上迈出了重要的一步,为大语言模型的训练优化和能力评估提供了新的思路和方法。