在时间序列分析领域,一个值得深思的现象持续存在:尽管模型架构经历了从循环神经网络到Transformer的重大演进,但训练过程中使用的损失函数却几乎一成不变地依赖于均方误差(MSE)这类点对点误差度量。这种"架构创新、损失停滞"的现状,反映出我们在方法论层面对损失函数统计假设的系统性反思不足。
传统点对点误差的核心假设在于,将标签序列中的各个时间步视为给定历史条件下相互独立的预测目标。然而,这种假设与真实世界时间序列数据的生成机制存在根本性矛盾。真实的时间序列数据由随机过程演化而来,不同时间点之间存在着复杂的相关关系。

重新审视损失函数的基本假设
当前主流的时间序列预测方法普遍采用逐时间点的均方误差作为损失函数:
$$\mathcal{L}{\text{MSE}} = |\mathbf{y} - g\theta(\mathbf{x})|^2=\sum_{t=1}^\mathrm{T}\left(y_t-g_{\theta,t}(\mathbf{x})\right)$$
这种损失函数隐式地做出了独立性假设:在给定历史序列的条件下,标签序列各时间点的观测值相互独立。但实证分析表明,真实时间序列中存在显著的标签自相关现象。即使采用频域变换或主成分分析等预处理方法,变换后的标签序列仍然存在残余相关性。
DistDF方法的理论基础
为解决传统方法的局限性,DistDF提出直接对齐预测序列的条件分布与真实标签的条件分布。这种方法的核心思想是通过最小化两个条件分布之间的距离来实现更准确的模型训练。
然而,直接估计条件分布距离面临严重的样本稀缺问题。对于给定的历史序列,数据集通常仅包含唯一的标签序列,模型也仅产生单一预测。这种"单样本"情形导致直接估计条件分布距离在统计上不可靠。

DistDF巧妙地利用概率恒等式将条件分布匹配问题转化为联合分布匹配问题。通过最小化历史-预测联合分布与历史-标签联合分布之间的Wasserstein距离,可以有效实现条件分布对齐,同时利用整个数据集的样本提升估计可靠性。
数学上,该方法基于最优传输理论证明了联合分布的Wasserstein距离构成了条件分布Wasserstein距离期望的上界:
$$\int \mathcal{W}_p\left(\mathbb{P}(\mathbf{y}|\mathbf{x}), \mathbb{P}(\hat{\mathbf{y}}|\mathbf{x})\right) d\mathbb{P}(\mathbf{x}) \leq \mathcal{W}_p \left(\mathbb{P}(\mathbf{y},\mathbf{x}), \mathbb{P}(\hat{\mathbf{y}},\mathbf{x})\right)$$
实现框架与技术细节
DistDF的具体实现包含三个关键步骤:首先构造联合序列,将历史序列与预测序列/标签序列组合;接着计算两个联合序列之间的Wasserstein距离;最后与传统的MSE损失进行加权融合。这种设计既保留了传统方法的稳定性,又引入了分布对齐的优势。

值得注意的是,DistDF作为模型无关的损失函数,可以与各类预测模型架构无缝集成。无论是基于RNN的经典模型还是最新的Transformer架构,都可以通过简单的损失函数替换获得性能提升。
实证研究与性能分析
在大量实验验证中,DistDF表现出了显著的优势。与通过标签变换削弱相关性的现有方法相比,DistDF通过直接最小化条件分布距离,实现了更彻底的偏差消除,从而获得了最佳的预测性能。
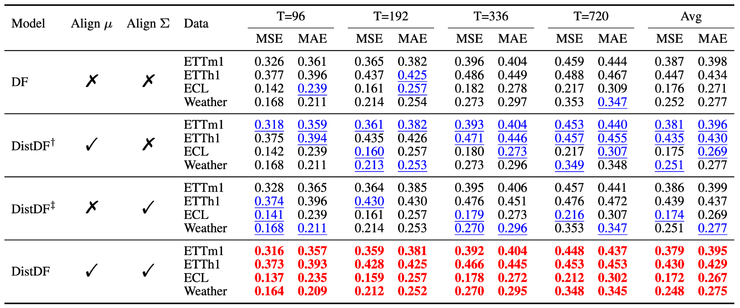
消融实验进一步验证了DistDF的两个关键因素:均值对齐和协方差对齐。单独实施任一种对齐都能带来性能提升,而二者同时实施时效果最为显著。这表明分布对齐的完整实现需要同时考虑一阶和二阶统计特性。
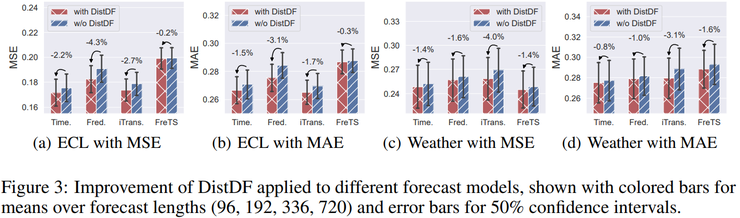
可视化分析显示,采用DistDF训练的模型能够更好地跟随序列中的突发变化,预测序列在整体形态上更接近真实数据。这不仅体现在数值误差的降低上,更重要的是模型学习到了真实未来时间序列的整体分布形态。
在多任务学习中的扩展应用
这项研究的启示超越了时间序列预测的范畴。在多任务学习场景中,传统损失函数往往隐含了"各任务标签相互独立"的假设,忽略了任务间的内在相关性。DistDF所倡导的联合分布对齐思想,为多任务学习提供了一种更为通用的损失函数构造范式。
兼容性实验表明,无论模型本身的复杂度和建模方式如何,引入DistDF训练策略后,模型预测性能几乎都能获得提升。这一结果强有力地证明了DistDF的作用并非弥补特定模型结构的不足,而是提供了更优质的训练信号。
行业影响与未来展望
这项研究对时间序列预测领域产生了深远影响。首先,它挑战了长期以来被默认的损失函数设计范式,促使研究者重新思考"应当优化什么"这一根本问题。其次,它为处理具有复杂相关结构的序列数据提供了新的技术路径。
在实践应用层面,DistDF的方法论可以广泛应用于金融时间序列预测、气象预报、工业设备故障预测等多个领域。这些应用场景的共同特点是数据具有显著的时间相关性,传统点对点损失函数难以捕捉其内在规律。
未来研究方向可能包括:扩展DistDF到更复杂的分布距离度量、研究自适应权重调整策略、探索在线学习场景下的分布对齐方法等。同时,该方法在语音合成、轨迹预测等序列生成任务中的应用也值得深入探索。
从更宏观的视角看,这项研究代表了机器学习领域的一个重要趋势:从单纯的模型结构创新转向对学习目标本身的深入思考。这种范式转变可能会催生更多基于统计理论和概率论的新型损失函数,推动整个领域向更理论化、系统化的方向发展。