AI推理成本的失控现状
近年来,人工智能领域的基础设施优化本应持续降低计算成本,但现实却出现了令人意外的逆转。具有强大智能体能力的应用如OpenClaw等现象级产品爆火的同时,API账单却呈现逆势飙升态势。除了智能体运作本身带来的海量上下文堆叠外,一个隐藏在背后的成本黑洞正在显现——越来越长甚至走向失控的思维链(Chain-of-Thought, CoT)。
OpenAI在2025年1月的财报电话会上透露,o1系列模型的平均单次请求token消耗达到GPT-4o的2.7倍,而在某些编程任务上这个倍数甚至冲到五倍以上。更令人震惊的是,新发布的GPT 5.4 Pro在回答一个简单的"Hi"问候时,竟需要5分18秒和80美元的成本。
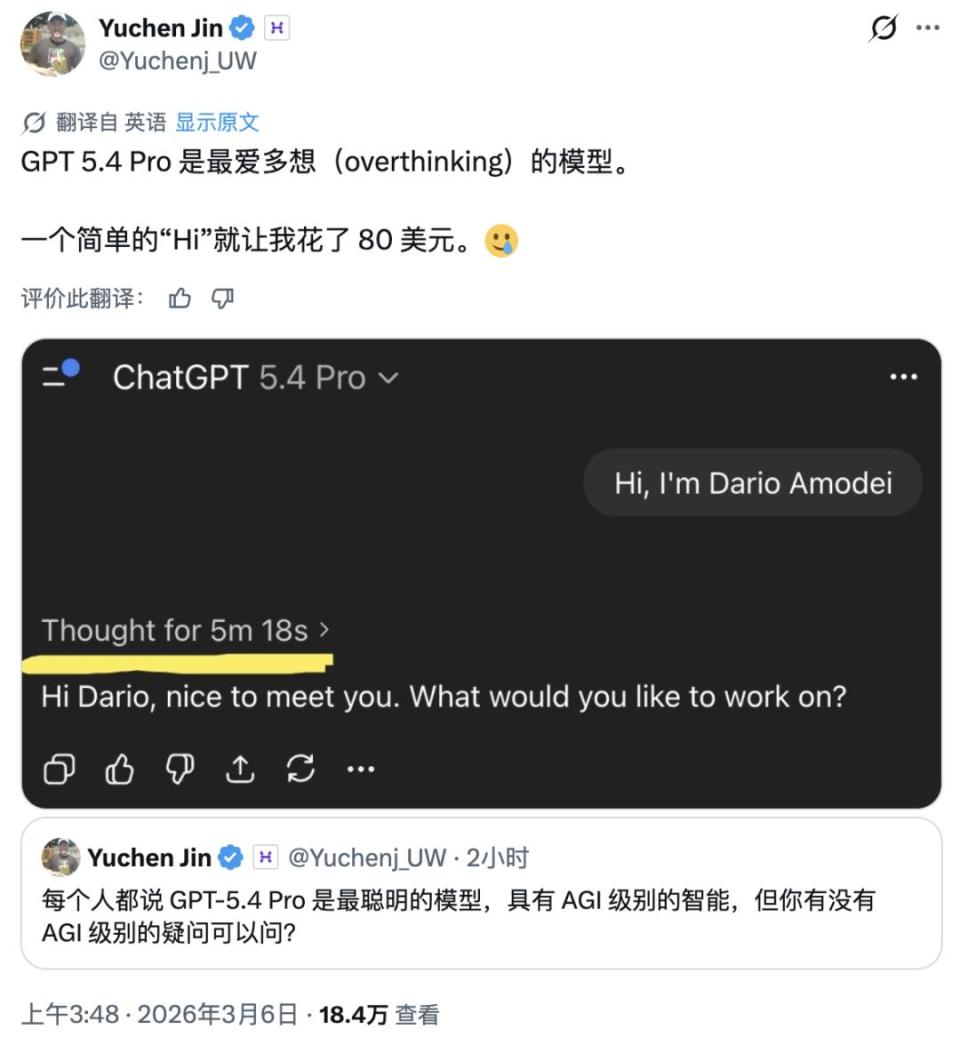
这种趋势引发了一个核心问题:如此漫长的思维链是否真的必要?何时才能真正产生价值?我们又该如何让模型实现少而精的思考?这些问题自o1模型诞生以来就一直困扰着研究界。
思维链长度与准确率的倒U型关系
思维链的概念其实早于GPT模型的出现。2022年,谷歌研究团队发表的两篇奠基性论文确立了CoT作为推理范式的地位。《Chain-of-Thought Prompting》展示了在少量示例中加入推理链可以大幅提升模型在算术、常识和符号推理等任务上的表现,某些情况下准确率能从接近零跃升至60%以上。而《Zero-shot CoT》提出的"Let's think step by step"提示词,则成为激活模型多步推理能力的标准方法。
随着CoT被证明有效,研究界自然产生了一个假设:更长的CoT应该更有效。2023年至2024年上半年,大量研究工作聚焦于如何让模型生成更长、更精细的推理链。方法包括提示工程诱导、强化学习奖励长推理流,以及使用大模型生成的长推理链来蒸馏小模型。
然而,在o1模型发布前半年,斯坦福大学的研究团队已经开始质疑这些长思维链的实际价值。他们发现,对于简单的小学算术题,模型往往会生成数百甚至上千tokens的推理文本,其中大部分是重复验算、自我质疑和多种解法尝试。令人惊讶的是,当手动剪短这些冗长推理时,答案正确率并未下降,有时甚至轻微上升。
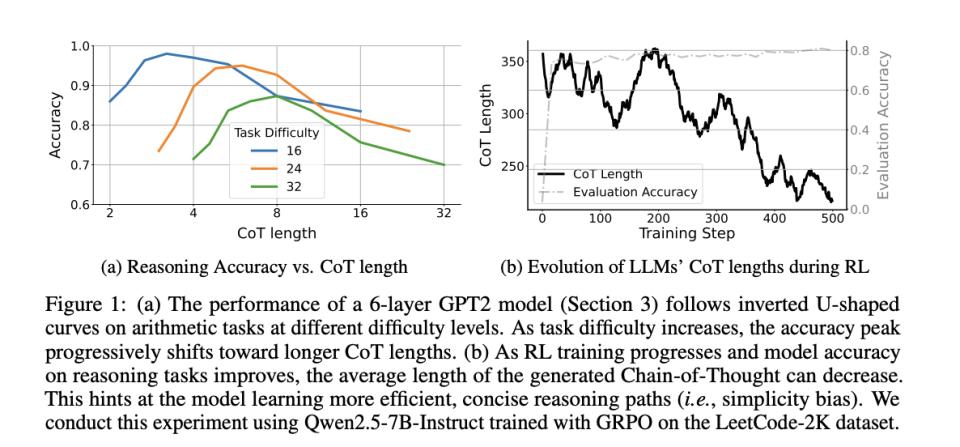
2025年5月,《When More is Less》论文为这一现象提供了精确的量化分析。研究显示,思维链长度与准确率之间存在明显的倒U型曲线关系。在不超过最优长度的区间内增加思考步骤确实有益,但超过临界点后准确率开始单调下降。更重要的是,这个最优长度随任务难度和模型能力动态变化——难题需要更长思考链,而能力更强的模型反而需要更短的思考链。
过度思考的三种模式与应对策略
过度思考现象主要表现为三种模式,每种都有其独特的成因和应对挑战。
线性展开模式是最经典的CoT形态,模型像打草稿一样一步步推进推理。问题在于模型缺乏停止判断能力,经常在得出答案后继续不必要的验算或重复解题。
反思循环模式中,模型生成初步答案后会触发自我质疑机制。这在复杂问题上确有价值,但在简单问题上过度反思就造成了资源浪费。
多路径采样模式为了提升鲁棒性而让模型生成多个推理轨迹,最后通过投票确定答案。虽然对复杂问题有效,但成本呈几何级数增长,且大量候选推理轨迹质量低下。
针对这些过度思考模式,业界提出了多种控制策略。最简单的方法是设置硬性token限制,但这种方法会限制模型解决复杂问题的能力。更精细的方法包括实时监测冗余信号的自适应推理,以及根据问题难度进行动态路由。然而,这些方法都依赖于间接指标,缺乏对思考质量的本质判断。
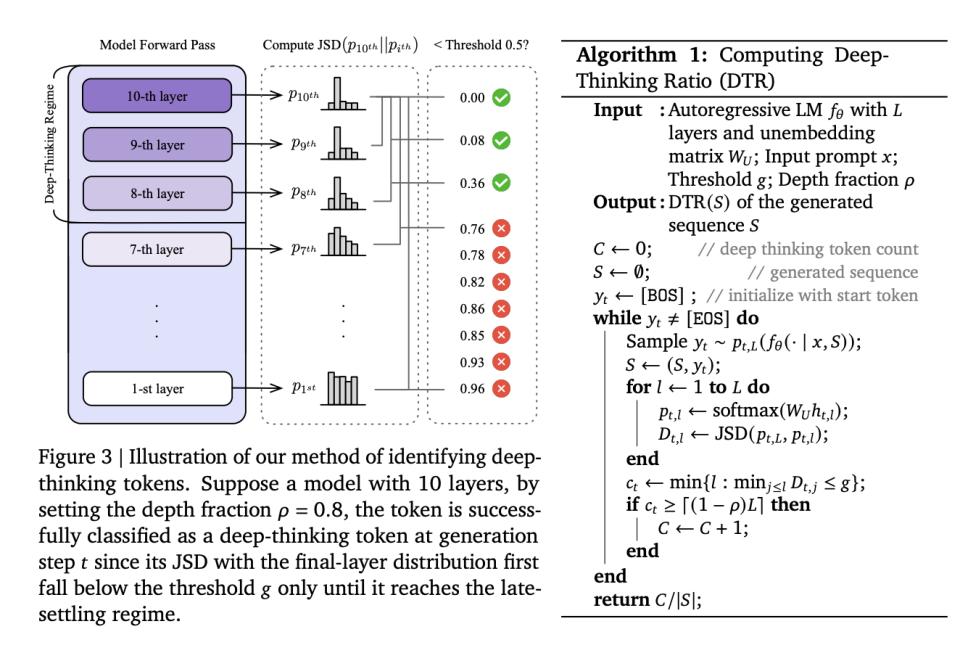
深度思考率:思考质量的新标尺
谷歌2026年2月的论文《Think Deep, Not Just Long》提出了一个突破性的解决方案——深度思考率(DTR)。这种方法的核心洞见是:直接观察Transformer架构内部的动态计算过程,而非仅仅关注表面文本特征。
当大模型生成每个token时,信号需要经过数十甚至上百层神经网络的传递与计算。研究发现,不同token在模型内部经历的"思考深度"存在显著差异。对于简单的语法词或常识性内容,预测概率在浅层就已锁定,后续层只是形式上的传递。而对于需要真正推理的关键token,预测会一直修正到深层才收敛。
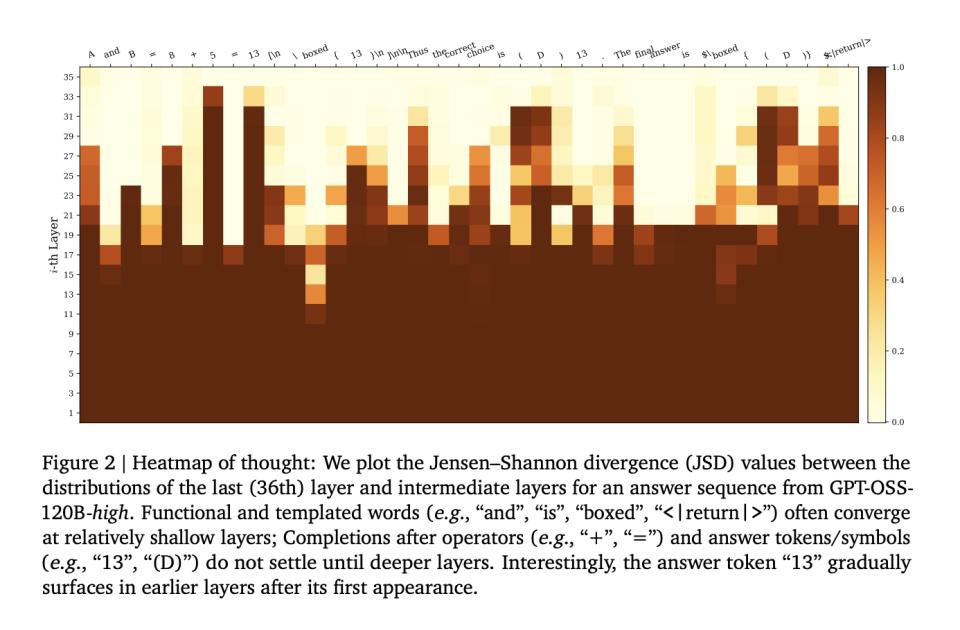
研究人员使用数学散度测量中间层与最终输出之间的分布差异,定义了DTR指标:在一段文本中,需要深层计算才能确定的token比例。高DTR意味着大部分token都需要深层计算,低DTR则表明文本主要由浅层套话组成。
这一指标完美解释了之前观察到的现象:冗长推理链中充斥着大量浅层套话,它们拉长序列但不产生实质思考;而短小精悍的推理链则高度浓缩,几乎每个token都需要深层计算。
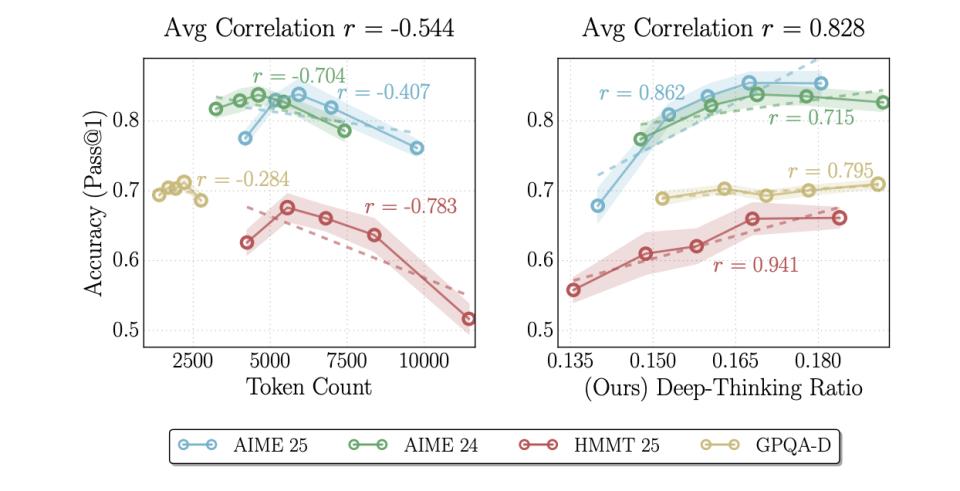
论文中的典型案例显示,回答同一几何题时,错误样本使用27724个tokens而DTR仅13.9%,正确样本仅用3725个tokens却达到19.0%的DTR。前者90%是废话,后者句句是干货。
基于DTR指标,论文提出了Think@n方法优化多路径采样模式。传统方法生成完整推理链再投票,而Think@n只让每个线程先生成50个词立即计算DTR,掐断低DTR线程,将算力集中于高潜力候选。实验证明,这种方法能用一半token达到或超越传统方法性能。
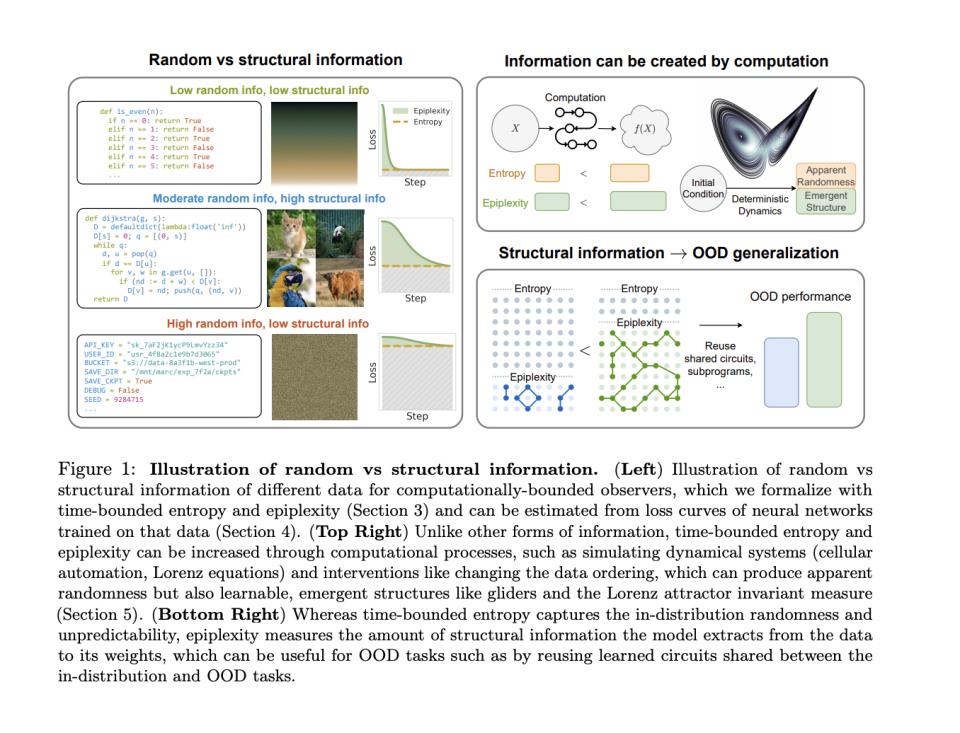
表观复杂性:思考价值的本质
DTR指标虽然能有效识别思考质量,但并未解释为什么深层思考更有效。卡耐基梅隆大学和纽约大学的联合研究《从熵到表观复杂性:为计算受限的智能体重塑信息论》为此提供了理论支撑。
传统信息理论关注的是随机性(熵),但这对解释AlphaGo等模型的成功存在局限。新研究提出,对于算力受限的智能体而言,数据的价值不在于其随机性,而在于包含的可学习结构复杂度——即表观复杂性(Epiplexity)。

随机生成的API密钥熵高但Epiplexity接近零,因为无法从中学习可迁移知识;而算法代码熵不高但Epiplexity高,因为理解它需要构建复杂内部表征。这解释了高DTR推理更有效的原因——它们在产生更多Epiplexity。
当模型进行深层推理时,它不是在简单检索记忆或应用表面规则,而是在实时构建新的认知结构。这些步骤的共同特点是它们为问题空间赋予额外结构,迫使模型构建新的内部模式。
这一视角将推理重新定义为结构信息的生成过程。高质量推理不仅仅是搜索解空间,更是在动态改变解空间的表征方式,让复杂问题变得简单。真正有价值的推理token是那些迫使模型发现新模式、提炼抽象规律的token,它们需要动用深层网络的全部计算能力。
从能力驱动到资源理性的转型
从CoT到过度思考再到深度思考的演变,反映了AI系统从能力驱动向资源理性转型的历史趋势。早期深度学习革命解决的是"能不能"的问题,test-time compute革命推动的是"能不能做更难任务"的问题。而现在,当这些能力逐渐成熟后,核心问题转变为"怎样做最经济"。
过度思考问题的凸显正是这一转型期的必然产物。DTR和Epiplexity不仅是测量工具,更代表了一种新的设计哲学:思考的价值不在于生成文本的数量,而在于文本背后调用的结构性计算量及其可迁移性。
在实际应用中,这一转变意味着我们需要重新评估AI系统的性能标准。传统的基准测试主要关注最终准确率,而未来可能需要同时考虑计算效率和资源消耗。对于企业用户而言,选择AI模型时不仅要看其能力上限,更要评估其在不同任务上的计算效率。
未来展望与应用前景
基于DTR的研究为AI推理优化开辟了多条可行路径。最直接的应用是在推理过程中实现动态资源分配,根据实时DTR值调整计算预算。更深远的影响可能体现在模型训练阶段,将DTR作为强化学习的奖励信号,从根源上培养模型的高效思考习惯。
在产业应用层面,这一技术有望显著降低AI服务的运营成本。对于需要大量推理的应用场景如代码生成、数学解题和复杂规划,优化后的模型可以在保持性能的同时将成本降低30-50%。这对于推动AI技术的大规模商业化具有重要意义。
然而,这一领域仍存在挑战需要克服。DTR的计算本身需要额外的监控开销,如何在不显著增加成本的情况下实现实时评估是关键问题。此外,不同模型架构和任务类型可能需要定制化的DTR阈值策略。
从更宏观的角度看,深度思考率的研究代表了AI发展的重要转折点:我们从追求更强大的模型转向追求更聪明的模型。这不仅关乎经济效益,更关系到AI技术的可持续发展。在算力资源日益紧张的背景下,高效思考能力可能成为下一代AI系统的核心竞争力。