在大语言模型逐步从通用推理工具走向专业领域应用的过程中,运筹优化成为一个极具吸引力同时也极具挑战性的方向。运筹优化问题天然具备清晰的数学结构和可验证的求解结果,看似非常适合由模型自动完成建模与求解。然而,真实运筹建模高度依赖变量定义、约束设计与目标函数之间的整体一致性,其推理过程往往呈现出强步骤依赖和强耦合特征。

传统方法的局限性
当前运筹建模大模型研究面临的核心困境是:模型在求解器层面得到正确结果,并不意味着其完成了正确的建模。在现有主流训练范式中,无论是仅依据最终求解结果进行奖励,还是对中间步骤进行局部、逐步的过程监督,都难以准确刻画运筹建模这种长链条推理任务的真实质量。
这种监督信号与任务本质之间的错位,使得建模错误可能被掩盖甚至被反复强化。例如,漏掉某个较松的约束或变量定义不严谨等错误,可能在特定实例里不影响最优值,却会让模型误以为这类建模逻辑可行,从而把不稳定甚至错误的建模方式固化下来。
StepORLM的创新架构
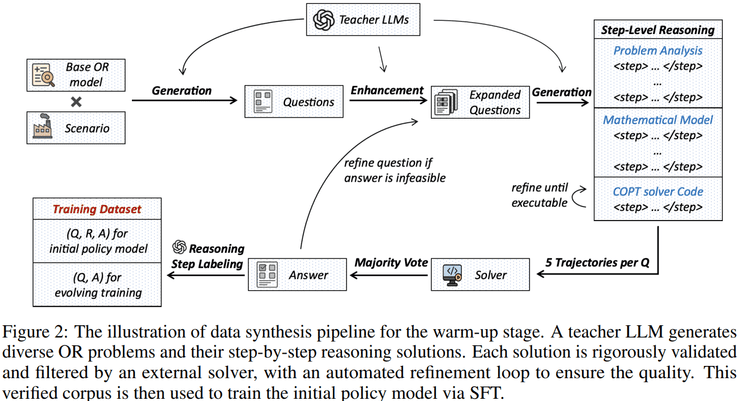
StepORLM采用"两阶段训练+自进化闭环"的设计思路。在第一阶段的warm-up过程中,研究团队构建了一个高质量的初始策略模型,使其具备基本的运筹优化建模能力。通过教师模型自动生成运筹优化问题,并经过改写、单位转换和参数缩放等方式增强问题多样性,最终构建了由问题及其对应的完整且正确推理轨迹组成的数据集。
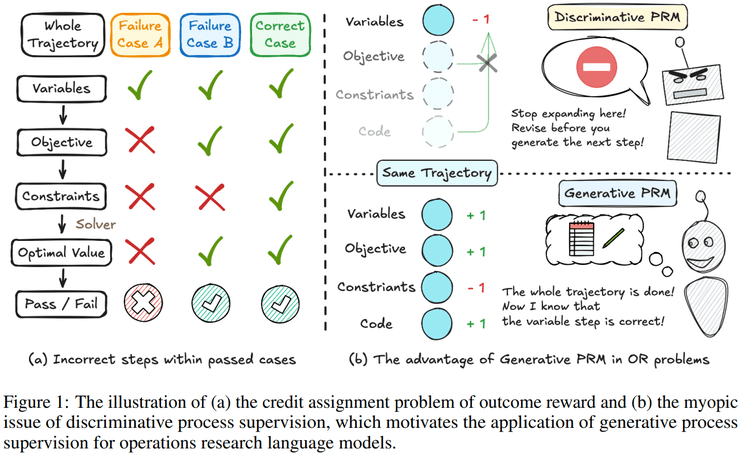
第二阶段是策略模型与生成式过程奖励模型协同进化的自进化训练阶段。这一创新设计使得系统能够同时维护两个模型:策略模型负责生成完整的OR解题轨迹,而GenPRM则从全局视角对整条推理过程进行回顾式评估。与传统过程奖励模型不同,GenPRM具备推理与综合判断能力,能够捕捉步骤之间的依赖关系。
实验验证与性能分析
在6个具有代表性的运筹优化基准数据集上的系统测试显示,StepORLM展现出显著优势。这些数据集涵盖了从相对简单的线性规划问题到高复杂度、贴近真实应用场景的工业级混合整数规划问题。
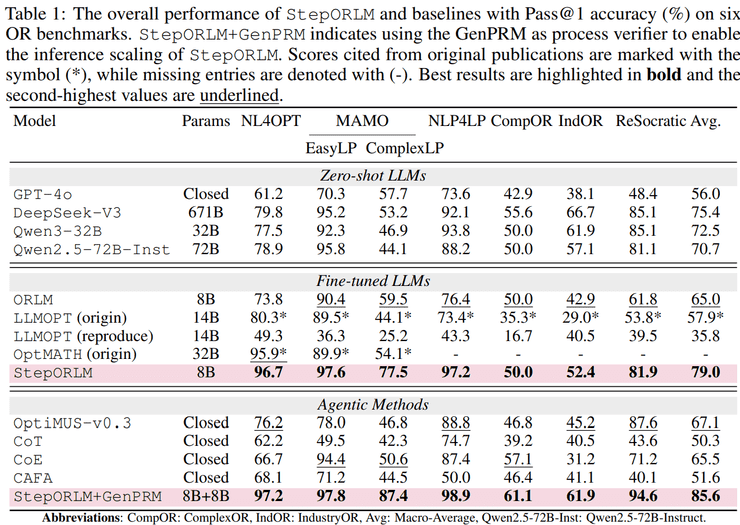
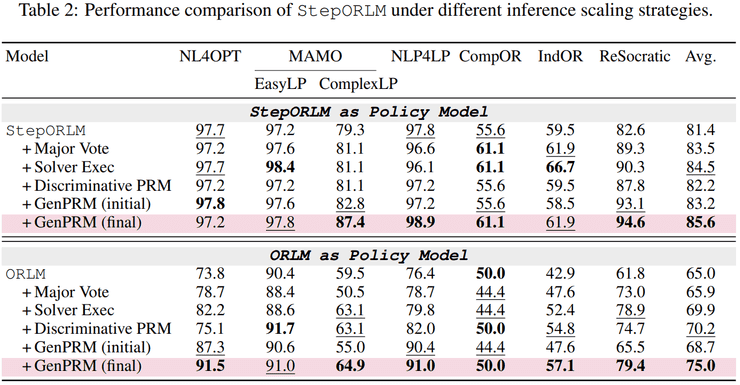
与零样本通用大语言模型相比,仅有8B参数规模的StepORLM在平均准确率上明显超过了DeepSeek-V3(671B)和Qwen2.5-72B等超大模型。这一结果表明,在运筹优化建模任务中,模型参数规模本身已不再是决定性因素,训练范式与监督信号设计才是性能提升的关键。
当StepORLM与GenPRM结合使用时,其平均Pass@1准确率可进一步提升至85.6%,并在最具挑战性的ComplexOR和IndustryOR数据集上分别取得了约9.9%和9.5%的显著增益。更重要的是,GenPRM学到的模型无关的运筹推理判据,能够为其他运筹优化模型带来接近10%的性能提升。
方法论意义与应用前景
从方法论角度来看,这项研究验证了一个关键认识:在运筹优化这类具有强步骤依赖特征的任务中,奖励模型本身若缺乏推理能力,将难以为策略模型提供有效监督。只有具备整体理解能力的过程监督,才能有效缓解归因错误和短视问题。
在运筹优化与大语言模型结合的研究领域中,StepORLM显著提升了模型在建模正确性、约束完整性以及实际应用可靠性等方面的表现。通过引入过程级监督与自进化训练机制,模型不仅能够生成形式正确的规划表达式,还能够构建逻辑一致、可被求解器稳定执行的完整运筹优化模型。
这项研究提出的训练范式对其他复杂推理任务同样具有启发意义。其强调的整体化、回顾式过程监督思想,可推广至数学证明、代码生成、科学建模以及其他长链条决策任务,为解决强依赖推理场景中监督信号失真的问题提供了一种具有普适性的思路。
技术细节与实现机制
StepORLM框架中的双源反馈机制是其核心创新之一。在每一轮训练迭代中,策略模型针对同一问题生成多条候选解题轨迹,并通过外部求解器和GenPRM两个渠道进行评估。这种设计确保了模型既关注最终结果的正确性,又重视推理过程的质量。
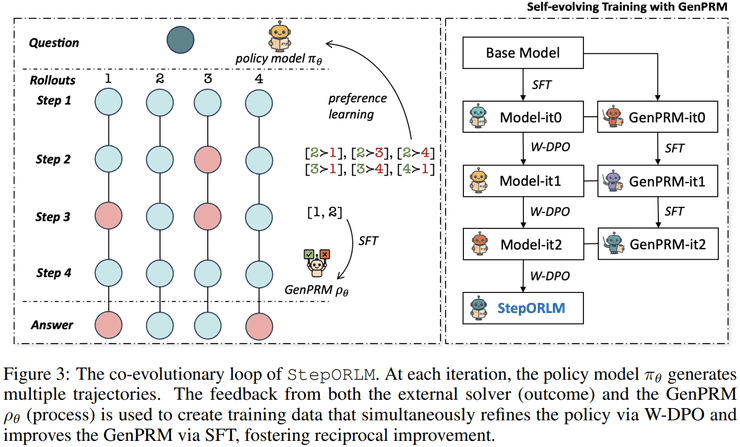
加权的Direct Preference Optimization方法的引入,使得系统能够区分严重建模错误与细微推理改进。这种精细化的权重分配机制,确保了训练过程能够有针对性地强化正确的建模逻辑,同时弱化错误的推理模式。
自进化训练闭环的建立,使得策略模型和GenPRM能够相互促进、协同进化。随着训练迭代的推进,策略模型生成的轨迹质量不断提升,为GenPRM提供更高质量的训练样本;而不断进化的GenPRM又能够为策略模型提供更精确的过程反馈,形成稳定的正反馈机制。
工业级应用潜力
StepORLM在IndustryOR等工业级数据集上的优异表现,预示着其在真实业务场景中的应用潜力。运筹优化在供应链管理、生产调度、资源分配等领域具有广泛的应用需求,但传统方法往往需要专家进行复杂的手工建模。
StepORLM的出现,使得自动化、智能化的运筹优化建模成为可能。模型不仅能够理解业务需求并将其转化为数学规划问题,还能够确保建模过程的逻辑一致性和可执行性。这对于降低运筹优化应用门槛、提升决策效率具有重要意义。
未来发展方向
虽然StepORLM在运筹优化建模任务上取得了显著进展,但仍存在进一步优化的空间。例如,模型在处理超大规模优化问题时的可扩展性、对动态环境变化的适应性等方面都需要继续探索。
此外,将类似的训练范式应用于其他类型的复杂推理任务,也是值得关注的研究方向。数学证明、科学计算、复杂决策等场景都可能从StepORLM所倡导的整体化过程监督思想中受益。
随着大语言模型技术的不断发展,我们有理由相信,类似StepORLM这样的创新训练范式将在更多专业领域发挥重要作用,推动人工智能从"会答题"向"会思考"的转变。