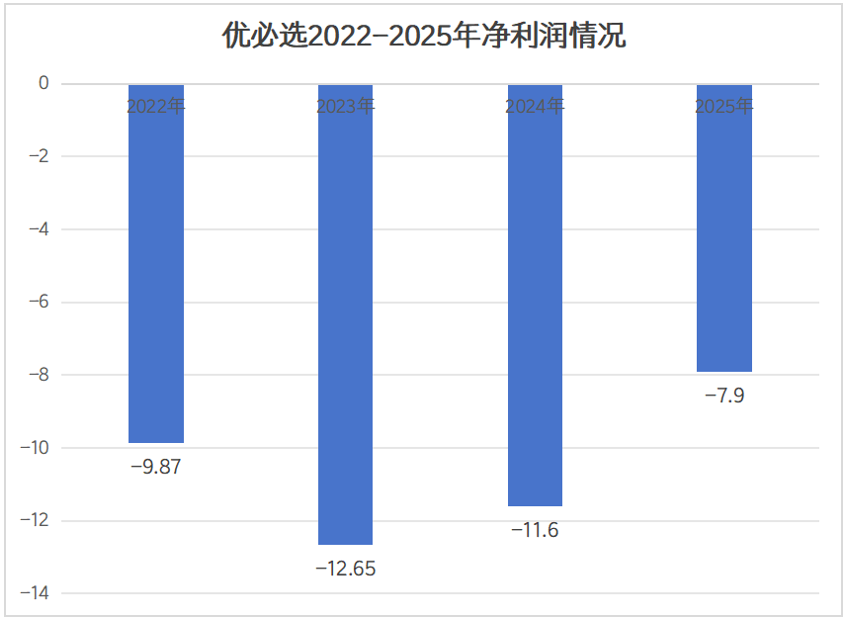
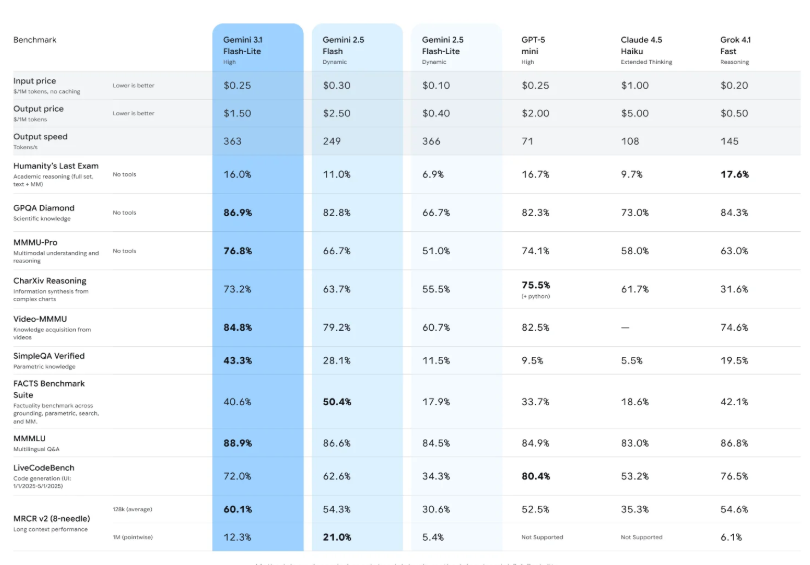
谷歌在AI模型优化领域再次迈出重要一步,最新推出的Gemini 3.1 Flash-Lite模型在性能与成本之间找到了新的平衡点。这款模型的设计理念体现了当前AI发展的一个重要方向——如何在保证质量的前提下实现极致的效率提升。
性能突破的技术基础
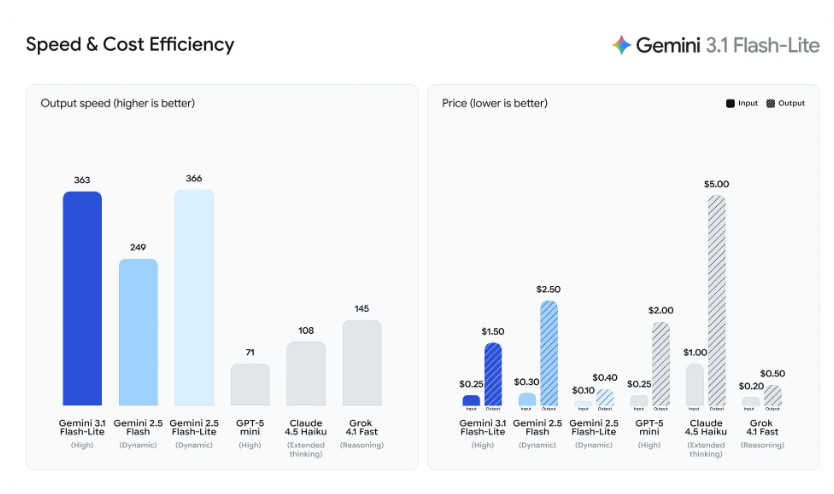
从技术架构角度来看,Gemini 3.1 Flash-Lite的2.5倍首字响应速度提升并非偶然。这种性能飞跃主要得益于谷歌在模型压缩和推理优化方面的深度创新。与传统模型相比,新版本采用了更加精细的参数剪枝策略,在保持核心能力的同时显著降低了计算复杂度。

在实际测试中,该模型展现出了令人印象深刻的多任务处理能力。特别是在需要即时反馈的应用场景中,其低延迟特性为开发者提供了更大的设计空间。这种性能优势不仅体现在纯文本处理上,在多模态理解和逻辑推理方面同样表现出色。
成本控制的商业价值
每百万输入Token仅0.25美元的定价策略,反映了谷歌对AI普及化的战略思考。这一价格水平相比市场上同类产品具有明显优势,为中小型企业和初创公司使用高质量AI服务创造了条件。从商业角度分析,这种定价模式可能重塑整个AI服务市场的竞争格局。
成本控制不仅体现在直接的使用费用上,还反映在部署和维护的间接成本中。由于模型体积的优化,所需的计算资源和存储空间都得到了有效控制,这进一步降低了整体拥有成本。
思考层级的创新设计
'思考层级'调节功能的引入,代表了AI模型设计理念的重要转变。这种可调节的推理机制允许开发者根据具体应用需求动态调整模型的'思考深度'。对于简单的文本翻译或内容分类任务,可以选择浅层思考模式以实现最大效率;而对于需要复杂逻辑推理的场景,则可以启用深度思考模式。
这种设计不仅提高了资源利用效率,还为AI应用提供了更大的灵活性。在实际应用中,开发者可以根据用户交互的实时需求动态调整模型的推理深度,从而实现更加智能和自适应的交互体验。
应用场景的扩展潜力
Gemini 3.1 Flash-Lite的性能特点使其特别适合需要实时交互的应用场景。在客服机器人、在线教育、实时翻译等领域,低延迟和高响应速度是确保用户体验的关键因素。同时,其成本优势也使得大规模部署成为可能。
在物联网边缘计算场景中,这种轻量级模型的价值更加凸显。由于边缘设备通常计算资源有限,对模型的效率和大小都有严格要求。Gemini 3.1 Flash-Lite的推出为边缘AI应用提供了新的技术选择。
技术发展的行业影响
从行业发展趋势来看,Gemini 3.1 Flash-Lite的发布可能引发一系列连锁反应。其他AI厂商很可能需要重新评估自己的产品策略,特别是在性能和成本的平衡方面。这种竞争将推动整个行业向更高效、更经济的解决方案发展。
对于开发者社区而言,这种高性价比模型的推出降低了AI应用开发的门槛。更多的创新团队将有机会尝试和部署AI技术,这可能催生出一批新的应用创新。
未来发展的技术展望
基于当前的技术突破,我们可以预见AI模型发展的一些新趋势。首先,模型的专业化程度可能会进一步提高,针对特定应用场景的优化将成为重要方向。其次,动态可调节的模型架构可能成为标准配置,以适应多样化的使用需求。
在技术层面,模型压缩和推理优化技术将继续深化发展。随着硬件技术的进步和算法创新的持续,我们可能会看到更多在保持性能的同时大幅提升效率的技术方案。
从长期来看,这种高性价比的AI模型发展路径将对整个数字经济发展产生深远影响。当AI技术真正实现普及化和民主化时,其对社会生产和生活方式的变革将更加深刻和广泛。
谷歌此次发布的Gemini 3.1 Flash-Lite不仅是一个技术产品,更代表了AI发展的重要方向。在追求更高性能的同时,如何让AI技术更加普惠和可及,将是整个行业需要持续探索的课题。