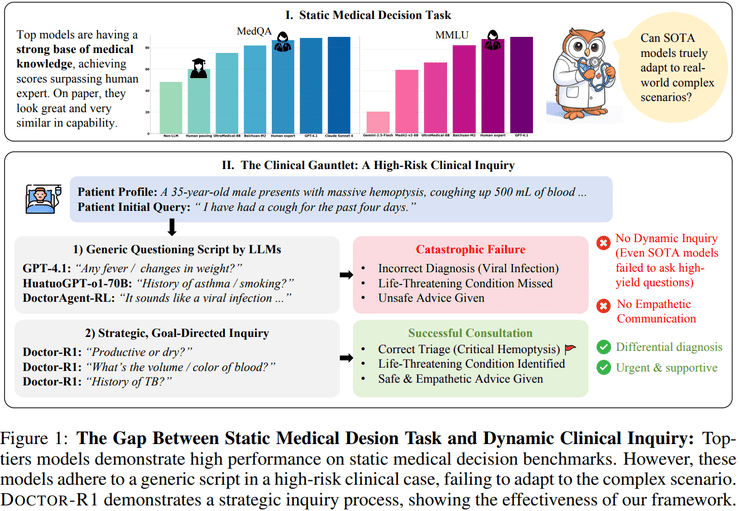
在医疗人工智能的发展进程中,一个引人深思的现象逐渐显现:传统评测框架下表现优异的大规模模型,在真实临床环境中往往难以胜任基本问诊任务。这种现象暴露了当前医疗AI评估体系的根本缺陷——过度强调静态知识获取而忽视了动态交互能力的培养。
静态评测与动态需求的错位
长期以来,医疗AI的能力评估主要依赖医学考试题和临床问答数据集等静态基准。在这种框架下,模型只需在信息完整的封闭条件下给出正确答案即可被视为具备较高医疗能力。随着大语言模型的突破性进展,多种系统在MedQA等测试中达到甚至超过人类专家水平,这曾让行业对医疗AI的成熟度产生乐观判断。

然而,真实医疗实践与静态评测存在本质差异。临床问诊是一个在高度不确定条件下,通过连续提问、风险识别与信息整合来逐步逼近决策的动态过程。模型在静态评测中展现的知识优势,并未自然转化为对真实问诊场景的可靠支持。研究显示,现有模型在多轮对话中普遍存在提问策略僵化、对高风险信号反应迟钝、过早形成结论以及缺乏基本沟通能力等缺陷。
DOCTOR-R1的创新方法设计
清华大学团队提出的DOCTOR-R1框架,从根本上重新定义了医疗智能体的训练范式。该研究不再将模型能力简单等同于知识覆盖度或参数规模,而是将临床问诊建模为部分可观测马尔可夫决策过程。这种建模方式更贴近真实医疗场景的特征——医生无法直接观测患者的完整病情状态,只能通过动态提问逐步获取关键信息。
研究团队采用强化学习而非传统的微调方法,核心原因在于两者所能学习的能力本质不同。微调主要教会模型在获取完整信息后如何生成回答,而临床问诊的关键在于模型在信息不完整的情况下,如何决定下一步应该询问什么信息。这一过程属于行动会改变未来可获取信息结构的序列决策问题,因此更适合用强化学习来建模。
突破性的实验结果
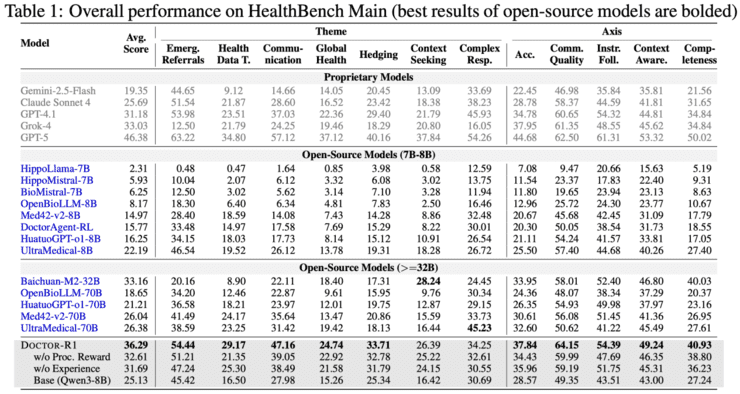
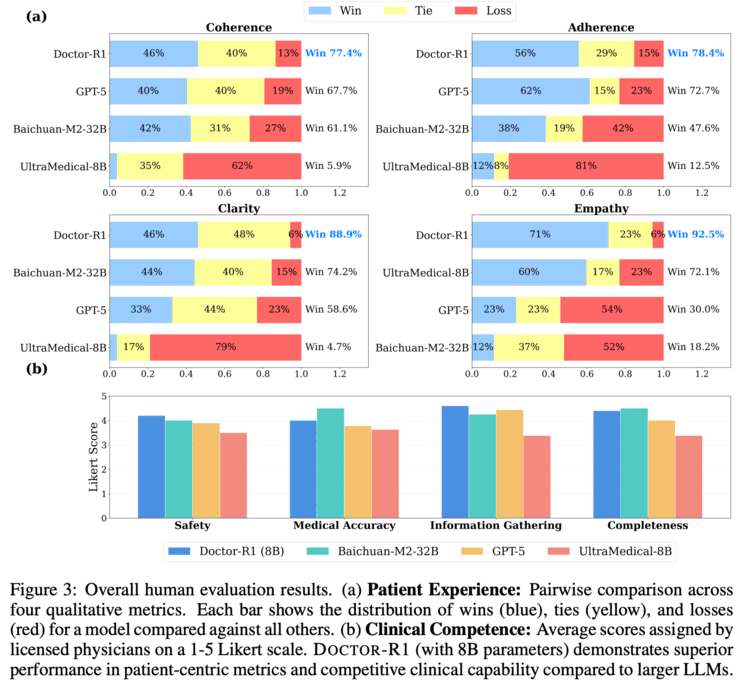
实验结果验证了研究假设的正确性。在参数规模仅为8B的条件下,DOCTOR-R1在多项动态问诊指标上超越了参数规模达32B甚至70B的知识型模型。特别值得注意的是,DOCTOR-R1从首轮对话开始即占据优势,并且随着对话推进持续扩大领先幅度,体现出"越问越准"的策略特征。
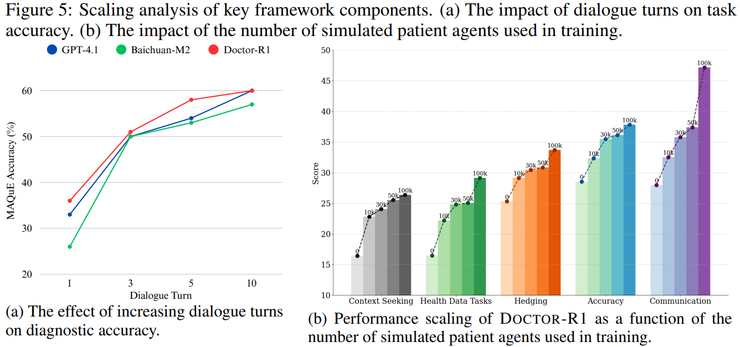
在HealthBench的沟通质量、上下文理解和回答完整性等指标上,DOCTOR-R1的提升幅度明显高于准确率本身。这表明良好的沟通与共情能力并非附带收益,而是其问诊策略的内在组成部分——共情表达有助于提高信息获取效率,这在真实医疗场景中至关重要。
关键机制设计的验证
通过系统的消融实验,研究团队验证了核心机制设计的有效性。当移除过程奖励、仅保留最终诊断奖励时,模型虽然仍能学习到正确的诊断结果,但中间问诊过程明显退化为模板化和低风险偏好模式。这证明如果不对提问过程本身进行显式奖励,模型会倾向于忽略如何提问这一关键能力。
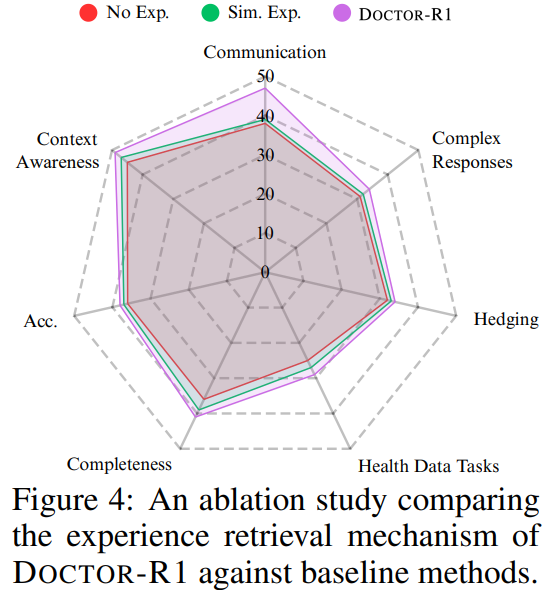
经验库机制的移除则导致模型在新场景中的适应能力显著下降,在相似病例上的表现也更加不稳定。这表明仅依赖on-policy强化学习不足以模拟真实医生通过长期经验积累形成的稳定问诊策略。高质量经验库的引入,使模型能够借鉴历史成功案例,提高在新情境下的决策质量。
创新性的奖励设计
研究提出的双层奖励机制解决了医疗AI训练中的两个关键难题。传统权重平均得分难以有效处理医疗决策中的否决型错误——即一次危险建议或严重误判无法被多次礼貌表达所抵消。分层惩罚机制将安全性、推理合理性和医学准确性置于最高优先级,一旦触发底线错误即直接给予强负奖励。
这种设计虽然约束严格,但能让模型守住临床安全的底线,更贴近真实医疗场景的风险要求。同时,过程奖励确保模型不会过早结束对话,而是通过系统性提问收集足够信息后再做出诊断决策。
多智能体交互环境的重要性
研究团队特别强调了多智能体交互环境对模型泛化能力的重要性。如果患者仅由固定脚本模拟,模型很容易学会针对特定脚本进行应对,从而在真实场景中表现出极差的泛化能力。为此,研究人员使用大语言模型扮演患者智能体,确保即便在相同疾病背景下,患者的表述方式、回答顺序以及风险信号的暴露时机都具有高度多样性。
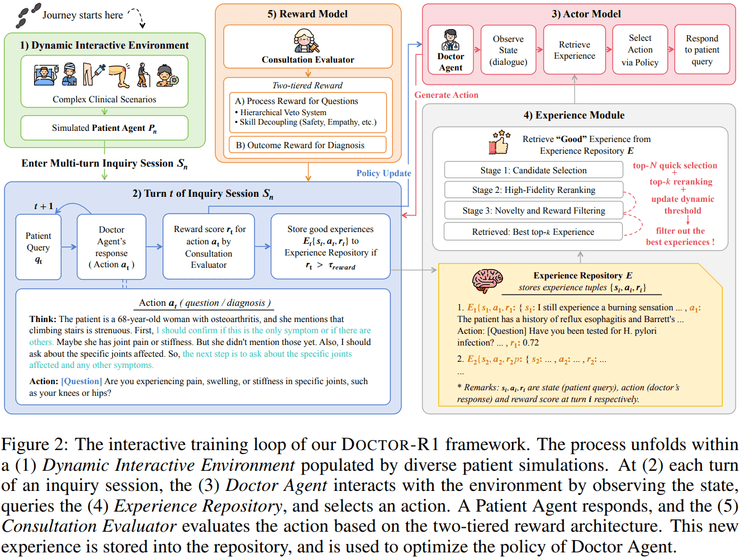
这种设计迫使医生智能体真正学习稳定有效的问诊策略,而非记忆固定套路。模型需要适应不同患者的个性化表达方式,并在对话过程中动态调整提问策略,这与真实医生的临床实践高度吻合。
经验库的智能化设计
在经验利用机制上,该研究实现了从简单记忆到智能检索的升级。经验库不再仅仅是存储历史对话的数据库,而是经过筛选的"高质量医生经验"。研究人员通过仅存储高奖励轨迹、在检索时同时考虑语义相似度与历史奖励,并引入新颖性约束,使模型能够有效借鉴成功经验而不陷入固定套路。
这种设计使模型在面对新患者时更接近一名积累了大量临床经验的医生,能够快速识别关键信号并采取适当的问诊策略。经验库的智能化检索机制确保了模型既能借鉴历史成功经验,又能保持对新情境的适应性。
对医疗AI发展的深远影响
这项研究对医疗人工智能领域具有明确的范式转换意义。首先,它表明当前医疗AI的瓶颈不仅受限于模型所具备的医学知识规模,还在于是否采用了与真实临床实践相匹配的训练范式。参数规模与模型能力并非简单的正比关系,合适的训练方法可能让较小模型在特定任务上超越更大模型。
其次,研究成功将以往被视为难以量化的软技能问题转化为可优化目标。通过合理的任务建模和奖励设计,共情表达、沟通质量以及对不确定性的处理等能力能够被稳定评估并持续强化。这为医疗AI融入更多人性化要素提供了技术路径。
最后,从方法论层面来看,研究提出的框架为真实世界智能体的构建提供了可复制的通用模板。其核心问题特征——不完全信息条件下的决策、面向长期目标的序列行为、高风险情境中的安全约束以及对经验积累机制的依赖——正是大多数真实世界智能体任务所共有的。
未来发展方向与挑战
尽管DOCTOR-R1取得了显著成果,医疗AI领域仍面临诸多挑战。真实临床环境的复杂性远超实验室模拟场景,模型需要应对更多不确定因素和边缘情况。此外,医疗AI的安全性和可靠性要求极高,任何错误都可能带来严重后果。
未来研究可能需要进一步探索如何将更多临床专业知识融入模型训练,如何确保模型在不同医疗场景下的稳健性,以及如何建立更完善的评估体系来全面衡量模型的临床适用性。同时,伦理规范和监管框架也需要与技术进步同步发展。
这项研究为医疗AI的发展指明了重要方向:从追求参数规模转向优化训练范式,从静态知识测试转向动态交互能力评估,从工具型系统转向具备临床推理能力的智能体。这一转变不仅将提升医疗AI的实际应用价值,也将推动整个人工智能领域向更智能、更安全、更实用的方向发展。