在多步时间序列预测任务中,预测性能随时间步长迅速退化几乎成为一种共识性现象。以气象预测为例,短期的温度变化能够较为准确地刻画,但当预测跨度扩展至数日甚至一周时,预测误差就会逐渐放大,周期与趋势结构逐渐偏离真实轨迹。类似的问题在金融价格走势和电力负荷预测等场景中也广泛存在。

无论模型结构如何演进,当预测范围从短期扩展至中长期时,误差积累、趋势漂移和结构失真往往不可避免地出现。这类现象在实践中被频繁观察,但传统研究通常将其归因于模型表达能力或依赖建模不足。然而,与模型结构持续创新形成鲜明对比的是,多步预测在训练阶段所使用的损失函数却长期保持固定。大多数方法仍以逐时间点的均方误差作为优化目标,默认将未来不同预测步视为相互独立且重要性一致的预测对象。
传统方法的局限性
当前时序预测领域普遍采用的均方误差损失函数存在两个关键性的先验假设:首先,它假设未来不同时间点的预测是相互独立的;其次,它默认所有预测步的重要性是相同的。然而,现实世界的时间序列数据往往违背这两个假设。明天的天气与后天的天气存在显著相关性,预测未来1小时和1周的任务难度也完全不同。
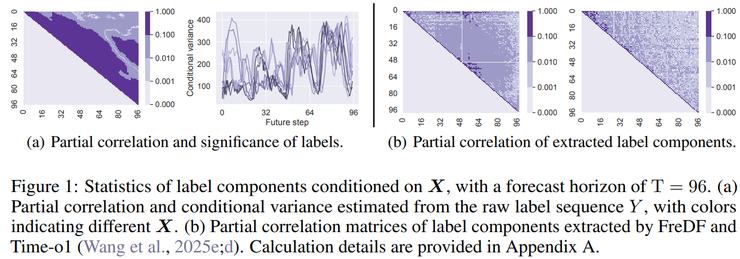
通过严格的实验验证,研究人员发现这两个先验假设在多步预测场景中均不成立。对标签序列的条件协方差进行偏相关分析显示,未来时间点之间存在大量非零偏相关系数,这直接否定了均方误差所隐含的条件独立假设。同时,对标签序列的条件方差分析表明,不同时间点的误差方差存在显著差异,且随着预测步整体增大,说明将所有预测步视为难度一致的任务并不符合数据特性。
QDF方法的创新突破
针对传统均方误差存在的结构性偏差,研究团队提出了QDF方法。该方法的核心创新在于将损失函数从固定不变的优化目标转变为可学习的对象,从而自动发现最适合特定任务数据结构的损失表述。
从概率建模的视角出发,理想的损失函数应来源于负对数似然。在高斯误差假设下,给定历史序列,标签序列的条件分布为多元高斯分布,其负对数似然可表示为包含权重矩阵的二次型。在这个二次型中,权重矩阵的非对角元素能够显式建模标签自相关效应,打破传统方法所隐含的条件独立假设;而对角元素则反映了不同预测步的不确定性差异,使得模型能够为不同难度的预测任务分配异构权重。
然而在实际应用中,权重矩阵的估计面临巨大挑战。为此,研究团队引入了元学习思想,通过双层优化机制将权重矩阵从数据中学习出来。该机制包括两个阶段:首先在给定权重矩阵的条件下,通过在元训练集上最小化损失函数来更新模型参数;然后依据模型在元验证集上的预测误差,反向传播更新权重矩阵。
这种设计的核心优势在于训练目标的优劣不再由拟合优度决定,而是由元验证集上的泛化性能来刻画。通过多次数据拆分与迭代更新,算法能够学习到在不同时间区间内一致的误差相关模式,从而形成稳定且可泛化的训练目标。
实验验证与性能分析
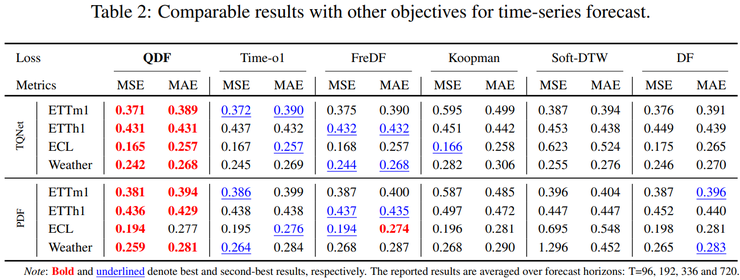
在广泛的实验验证中,QDF方法展现出显著优势。与现有的损失函数方法相比,包括通过标签变换削弱标签相关性的FreDF和Time-01等方法,QDF在稳定性和性能上限方面都表现更优。这些传统方法仅部分处理标签之间的相关性,仍隐含地假设剩余误差可通过均匀加权方式进行优化。
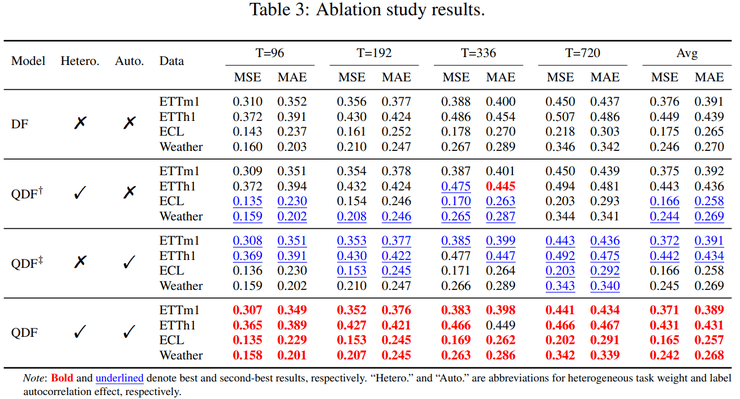
通过系统的消融实验,研究人员验证了QDF方法中两个关键因素的有效性。实验分别考察了仅建模不同预测步权重、仅建模时间相关性以及同时建模二者的情形。结果显示,两种因素单独引入时均能带来性能提升,而二者同时作用时效果最为显著,这充分证明了QDF方法设计的合理性。
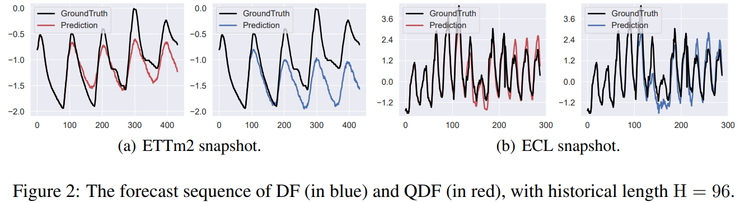
对模型输出的预测序列进行可视化分析进一步证实了QDF的价值。基于均方误差训练的模型在周期性时间序列中普遍存在振幅压缩、峰值被抹平以及拐点响应滞后的现象。而引入QDF后,模型在峰值位置、周期相位以及长期趋势稳定性方面均表现出更高一致性,时间结构得到了更完整的保留。
方法论意义与研究启示
这项研究的重要意义不仅在于提出了一个有效的技术方案,更在于它对整个时间序列预测领域研究范式的革新。首先,研究推翻了一个长期被默认接受的假设:多步预测可以被视为多个相互独立且等权重的回归任务。这一假设在实践中被广泛采用,却缺乏系统性的经验验证。
其次,研究展示了一种新颖的研究方法:将损失函数本身视为可以被学习的对象。不同于传统通过超参数调节或启发式设计的方式,该方法通过引入结构化的权重参数来显式建模标签间的关联性和不同预测步的重要性差异,并通过双层优化机制直接利用未见数据上的泛化误差学习权重参数。
从更广阔的视角来看,这项研究为元学习思想在时间序列预测领域的应用提供了理论和实践参考。它展示了如何将元学习的思想与领域特定的统计方法有机结合,形成既符合统计建模原理又具有良好泛化能力的训练目标。
实际应用前景与挑战
QDF方法在多个实际应用场景中展现出巨大潜力。在气象预测领域,该方法能够显著改善中长期天气预报的准确性;在金融时间序列预测中,它可以更好地捕捉价格波动的相关性和不确定性;在电力负荷预测方面,QDF有助于提高峰谷时段的预测精度。
然而,该方法在实际部署过程中也面临一些挑战。双层优化机制的计算复杂度相对较高,可能需要针对具体应用场景进行优化。此外,权重矩阵的学习需要足够的历史数据支持,在数据稀缺的场景中可能面临过拟合风险。
未来研究方向包括开发更高效的优化算法、探索先验知识的引入方式以及研究小样本场景下的适应性策略。随着计算资源的不断进步和算法优化的持续深入,QDF方法有望在更多实际场景中发挥重要作用。
技术发展趋势展望
时间序列预测作为机器学习的重要分支,正在经历从模型结构创新到训练机制优化的转变。QDF方法代表了这一趋势的重要方向,它表明通过重新思考训练目标的设计,我们可以在不改变模型架构的前提下显著提升预测性能。
随着物联网、智能城市等应用的快速发展,时间序列数据的规模和复杂度将持续增长。这对预测方法提出了更高要求,需要既能处理大规模数据,又能保持预测准确性的解决方案。QDF方法为这一需求提供了有前景的技术路径。
同时,该方法也启发了对其他机器学习任务中损失函数设计的重新思考。在许多实际应用中,传统的损失函数可能无法充分捕捉任务的特有结构,通过数据驱动的方式学习更合适的损失函数形式,有望带来更广泛的性能提升。

这项研究不仅为时间序列预测领域提供了实用的技术工具,更重要的是它展示了一种批判性思考和系统性创新的研究方法。在人工智能技术快速发展的今天,这种对基础假设的重新审视和对核心方法的根本性创新,对于推动整个领域的进步具有深远意义。