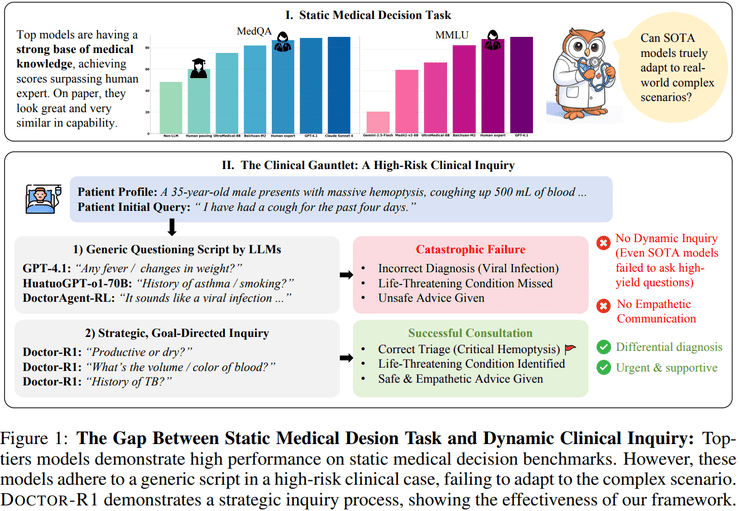
在医疗人工智能的发展历程中,评估方式在很大程度上决定了技术演进的方向。过去医疗AI的进步主要围绕医学知识获取与推理展开,模型能力的衡量标准通常是医学考试题、临床问答数据集等静态基准。在这种评价框架下,模型只需要在信息完整的封闭条件下给出正确答案,就被认为具备较高的医疗能力。
随着大语言模型的兴起,这一路径取得了突破性进展,多种系统在MedQA等测试中达到甚至超过人类专家水平。然而当这些模型被引入真实临床交互场景时,一个长期被掩盖的问题开始显现:真实的医疗实践并非基于完整信息给出诊断,而是通过连续提问、风险识别与信息整合来逐步逼近决策的动态过程。

静态评测与动态问诊的差距
研究发现,在静态医学问答任务中表现优异的模型,在需要多轮交互的动态临床问诊环境中会出现系统性失效。这种失效并非源于医学知识储备不足,而是体现在问诊策略层面:
- 提问顺序缺乏针对性,倾向于使用信息增益较低的标准化问题
- 在患者给出潜在高危信号后,难以调整提问路径
- 关键信息尚未充分收集的情况下过早形成判断
- 沟通方式与真实医疗场景不匹配,表现为共情不足、语气武断
由于这些问题在MedQA、MMLU等静态评测中几乎不会暴露,传统评测方式对模型真实临床能力存在严重失真。
创新性的训练方法论
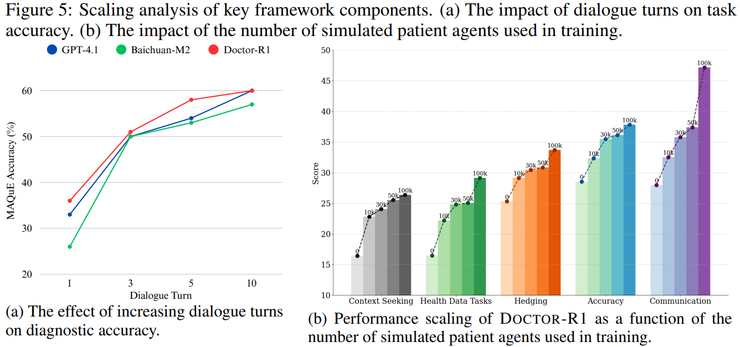
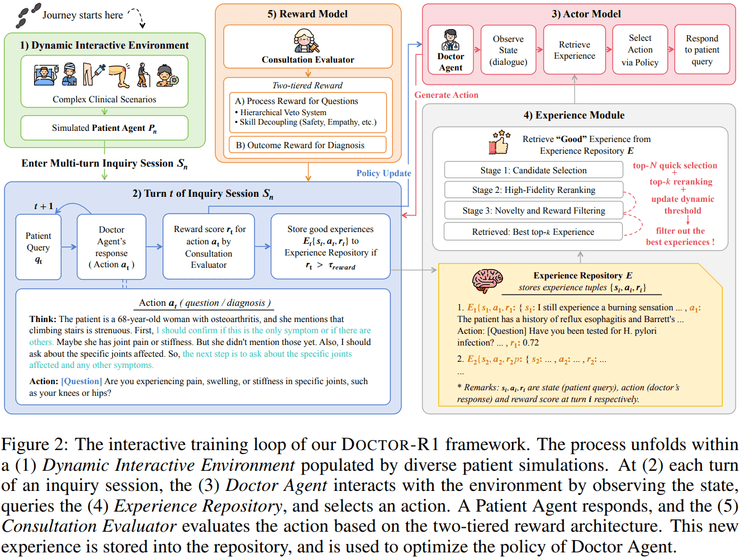
研究团队采用强化学习而非单纯的微调方法,核心判断在于两者所能学习的能力本质不同。微调主要教会模型在获取完整信息后如何生成回答,而临床问诊的关键在于模型在尚不清楚答案的情况下,如何决定下一步应该询问什么信息。
这一过程本质上属于行动会改变未来可获取信息结构的序列决策问题,因此更适合用强化学习来建模。更重要的是,研究人员将问诊过程建模为部分可观测马尔可夫决策过程,真实病情状态对医生模型不可见,医生所获得的观察信息具有噪声和不完整性。
多层次奖励机制设计
研究提出的双层奖励机制解决了两个关键难题:如果仅依据最终诊断结果给予奖励,模型会倾向于过早猜测并提前结束对话;医疗决策中存在的否决型错误需要特殊处理。
研究人员引入了分层惩罚机制,将安全性、推理合理性和医学准确性置于最高优先级,一旦触发底线错误即直接给予强负奖励。这种设计虽然约束严格,但能让模型守住临床安全的底线,更贴近真实医疗场景的风险要求。
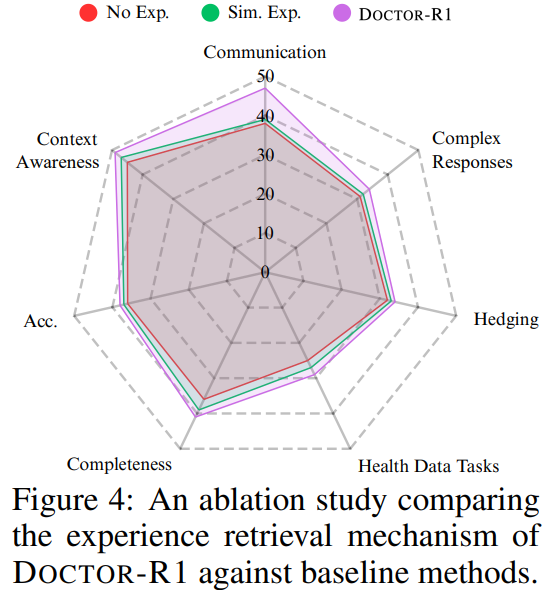
经验库的重要性
研究团队将经验库定位为经过筛选的"高质量医生经验",通过仅存储高奖励轨迹、在检索时同时考虑语义相似度与历史奖励,并引入新颖性约束,使模型在面对新患者时更接近积累了大量临床经验的医生。
当经验库机制被移除时,模型在新场景中的适应能力显著下降,在相似病例上的表现也更加不稳定,对话策略波动明显增大。这表明仅依赖on-policy强化学习不足以模拟真实医生通过长期经验积累形成的稳定问诊策略。
实际应用价值与启示
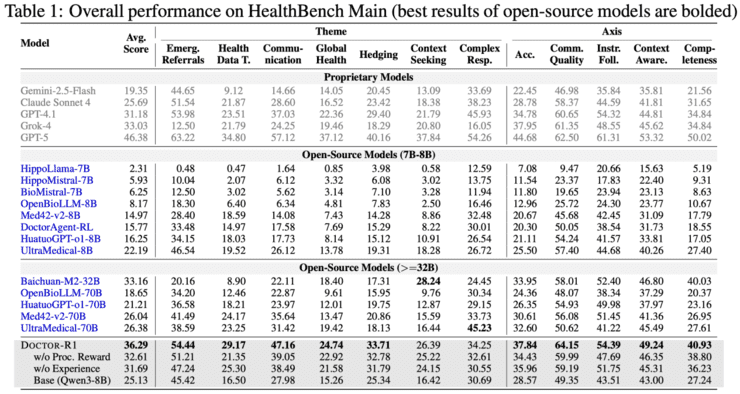
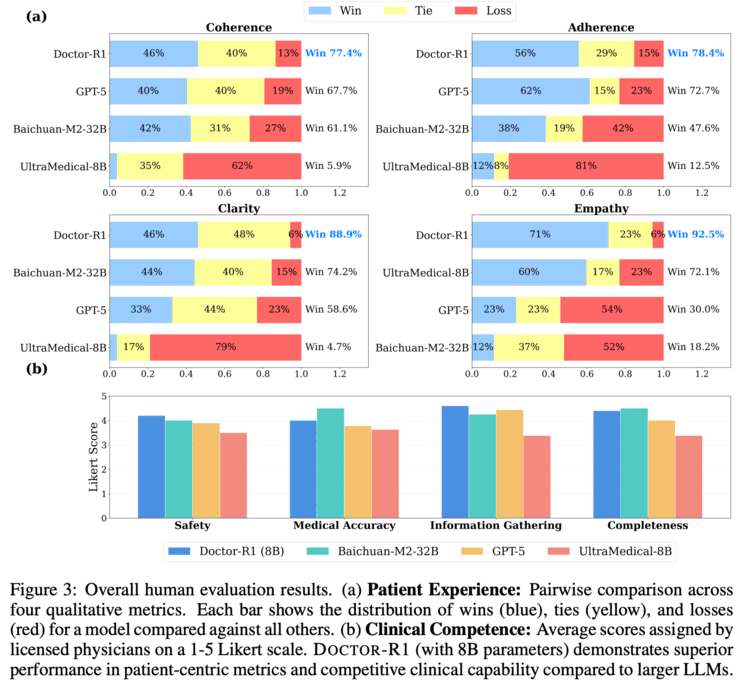
这项研究对医疗AI领域具有深远启示。首先表明当前医疗AI的瓶颈不仅受限于模型的知识规模,更在于是否采用了与真实临床实践相匹配的训练范式。参数规模仅为8B的模型在合适的强化学习框架下,能够在多项动态问诊指标上超过参数规模更大的知识型模型。
其次,研究将以往被视为难以量化的软技能问题转化为可优化目标。通过合理的任务建模和奖励设计,共情表达、沟通质量等能力能够被稳定评估并持续强化,验证了软技能可以纳入统一的训练体系。
对其他领域的借鉴意义
从方法论层面来看,这项研究为真实世界智能体的构建提供了可复制的通用模板。其核心问题特征包括不完全信息条件下的决策、面向长期目标的序列行为、高风险情境中的安全约束以及对经验积累机制的依赖,这些特征正是大多数真实世界智能体任务所共有的。
特别是在高风险决策领域,如金融风险评估、安全监控、紧急响应等场景,都需要智能体在信息不完整的条件下做出谨慎而有效的决策。这项研究提供的框架为解决这类问题提供了重要参考。
未来发展方向
基于这项研究成果,医疗AI的未来发展可能呈现以下几个趋势:
- 训练范式的根本转变:从以知识记忆为中心转向以决策过程为中心
- 评估体系的重新构建:动态交互能力将取代静态知识测试成为主要评估标准
- 多模态信息的整合:除了文本对话,还将整合视觉、听觉等感官信息
- 个性化适应能力:模型需要学会根据不同患者的特性和需求调整问诊策略
这项研究不仅为医疗AI的发展指明了新方向,也为整个人工智能领域如何更好地适应真实世界复杂环境提供了重要启示。随着技术的不断成熟,我们有理由相信人工智能将在更多高风险决策领域发挥重要作用。