数据治理:AI时代被忽视的核心竞争力
在人工智能技术快速迭代的今天,大多数企业将注意力集中在模型算法的选择上,却忽略了更为基础的数据治理环节。实际上,数据质量直接决定了AI应用的成败。根据行业实践,在生成式AI应用中,数据治理的影响力超过90%。这意味着,即使拥有最先进的模型,如果缺乏高质量的数据支撑,AI应用也难以发挥预期效果。

数据治理的餐饮业比喻:从食材采购到菜品制作
理解数据治理的重要性,可以借助一个生动的餐饮业比喻。假设一家餐馆的后厨需要准备食材:农场运送来的原始食材相当于企业的非结构化数据,这些数据需要经过清洗、分类、切割等处理步骤,才能成为可用的烹饪原料。
亚马逊云科技的Amazon EMR服务就扮演着"食材预处理"的角色。这项服务能够将企业数据仓库中的原始数据进行规范化处理,按照业务需求进行归类整理。例如,如果需要分析客户行为数据,就需要将原始日志数据转换为结构化的行为标签;如果要进行文本分析,就需要对非结构化文本进行分词和向量化处理。

向量数据的处理过程特别值得关注。就像采购回来的蔬菜需要根据不同的烹饪需求进行不同方式的切割处理,企业数据也需要根据具体的AI应用场景进行适当的向量化处理。这种处理不是简单的格式转换,而是需要充分考虑后续模型的使用需求,确保数据表征能够准确反映业务特征。
向量数据库:AI应用的"智能冰箱"
处理完成的数据需要有一个高效的存储和管理系统,这就是向量数据库的作用。向量数据库可以类比为餐馆的智能冰箱,它不仅能够安全存储处理好的食材,还能够根据菜品的类别进行智能分类,确保厨师在需要时能够快速找到合适的原料。

在现代AI架构中,向量数据库承担着关键角色。以Amazon Aurora、Amazon RDS和Amazon OpenSearch为代表的向量数据库解决方案,为企业提供了高效的数据检索和管理能力。这些数据库不仅支持传统的关系型数据存储,还专门优化了对向量数据的支持,能够快速完成相似性搜索和最近邻查询等AI应用的核心操作。
深度学习的应用过程就像客人点餐后厨师的烹饪过程。当一个查询请求到达时,AI系统需要从向量数据库中快速检索相关的数据片段,然后通过模型推理生成最终结果。这个过程的效率和准确性很大程度上取决于向量数据库的设计和数据质量。
数据治理的技术实现路径
企业实施数据治理需要遵循系统化的技术路径。下面的图示展示了AI应用企业领域数据实施的完整模式:
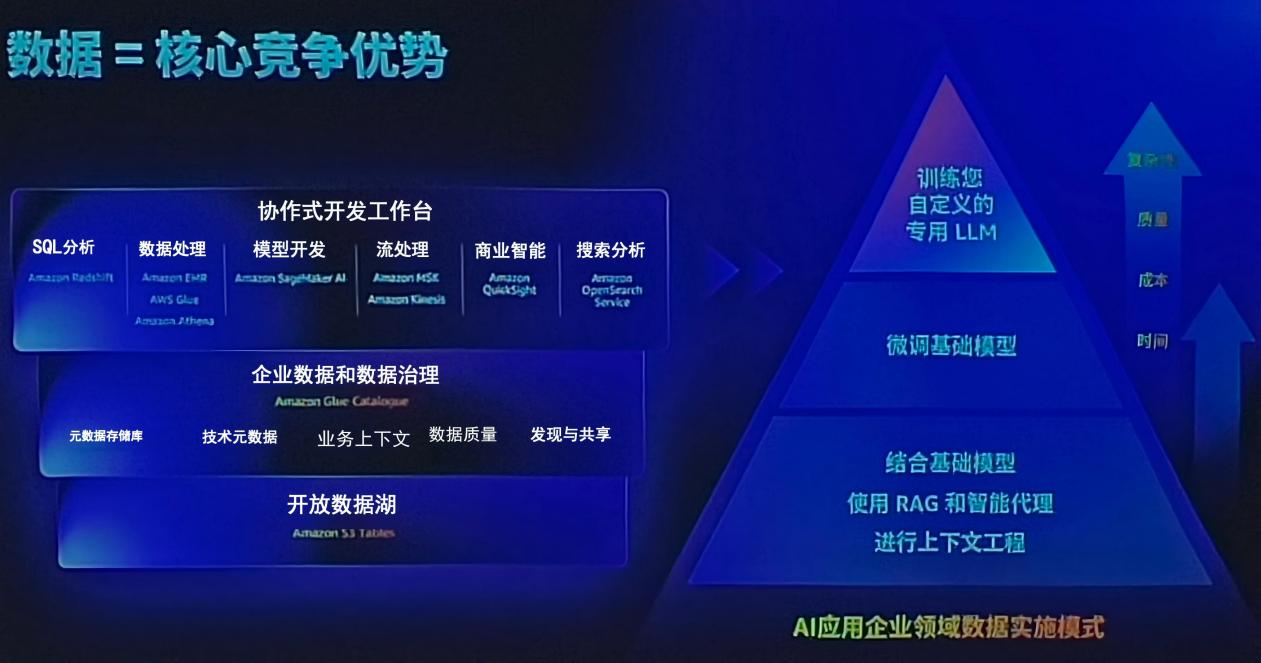
从技术架构的角度看,数据治理涉及多个关键环节。首先是数据采集和预处理,确保原始数据的完整性和准确性;然后是数据标准化和规范化,消除数据孤岛,建立统一的数据标准;接着是数据质量评估和监控,建立持续的数据质量管理机制;最后是数据安全性和合规性保障,确保数据使用符合相关法规要求。
模型训练与数据治理的关系
理解模型训练与数据治理的关系,可以用人才培养的过程来类比。一个人从幼儿园到大学的完整教育过程相当于基础大模型的训练,这个过程需要大量的通用数据和长时间的训练。而企业针对特定业务场景的模型优化,则类似于员工上岗前的专业培训。

微调(Fine-tuning)技术让企业能够在通用大模型的基础上,通过特定领域的数据进行针对性优化。这就好比新员工入职后接受的专业培训,使其快速掌握行业特定的知识和技能。这种方法的优势在于既保留了通用模型的基础能力,又具备了领域专业性。
知识蒸馏(Knowledge Distillation)是另一种重要的技术手段。它通过将大型模型的知识压缩到小型模型中,实现在资源受限环境下的高效推理。这个过程可以比作资深员工向新员工传授经验,用最有效的方式传递核心知识。
企业拥抱AI的"黄金三角"框架
基于数据治理的重要性,企业可以建立一个"场景-数据-人才"的黄金三角框架来系统化推进AI应用。
场景选择是企业AI应用的起点。企业需要识别那些既具有业务价值又适合AI技术解决的具体场景。智能客服、知识库构建、内容生成等都是典型的应用场景。关键是要明确每个场景的输入输出要求以及预期的业务价值。

数据基础是AI应用成功的保障。企业需要建立完善的数据治理体系,包括数据采集、存储、处理和分析的全流程管理。特别是要注重数据质量的建设,确保训练数据的准确性、完整性和时效性。
人才团队是推进AI应用的关键支撑。数据工程师、算法工程师、业务专家需要协同工作,共同推进AI项目的落地。企业需要建立跨职能的AI团队,确保技术能力与业务需求的深度结合。
数据治理的技术发展趋势
随着AI技术的不断发展,数据治理领域也在经历快速演进。以下几个趋势值得关注:
首先是自动化数据治理工具的普及。传统的数据治理需要大量人工参与,而现代AI技术使得自动化数据质量检测、数据分类和标签生成成为可能。这将显著提高数据治理的效率和规模。
其次是隐私保护技术的创新。在数据使用和隐私保护之间取得平衡是数据治理的重要挑战。差分隐私、联邦学习等新技术使得企业能够在保护用户隐私的同时充分利用数据价值。
最后是实时数据治理能力的提升。传统的批处理式数据治理难以满足实时AI应用的需求。流式数据处理和实时质量监控技术的发展,使得企业能够实现对数据质量的持续监控和即时修正。
数据治理的投资回报分析
企业在数据治理上的投入需要从长期价值的角度进行评估。短期来看,数据治理需要显著的投资,包括技术平台建设、团队培养和流程改造。但长期而言,高质量的数据治理能够带来多方面的收益。
首先是AI应用成功率的提升。良好的数据治理直接提高了模型训练的准确性和稳定性,减少了AI项目失败的风险。其次是运营效率的提高。标准化的数据管理减少了数据冗余和处理环节,降低了数据维护成本。最后是创新能力的增强。高质量的数据资产为企业提供了更多的业务洞察和创新机会。
实施数据治理的实践建议
基于行业最佳实践,企业在推进数据治理时可以遵循以下建议:
首先是从小规模试点开始。选择一两个关键业务场景作为数据治理的试点项目,积累经验后再逐步推广。其次是建立跨部门的数据治理委员会。数据治理涉及多个业务部门,需要高层的支持和协调。然后是制定明确的数据标准和流程。统一的数据标准是有效治理的基础。最后是建立持续改进机制。数据治理是一个持续的过程,需要定期评估和优化。

在AI技术快速发展的背景下,数据治理已经从可选项变成了企业数智化转型的必选项。只有建立坚实的数据基础,企业才能真正释放AI技术的潜力,在数字化竞争中占据优势地位。随着技术的不断进步,数据治理的方法和工具也将持续演进,为企业创造更大的价值。