随着人工智能模型参数规模向万亿级别迈进,支撑其训练的GPU集群已成为当今最复杂且最脆弱的计算系统。这些庞大的计算集群在运行过程中面临着前所未有的稳定性挑战,其中最为棘手的问题就是硬件故障的检测与预防。
GPU集群监控的技术挑战
在传统Web开发环境中,服务器性能问题通常可以通过简单的扩容策略来解决。然而,在AI训练场景中,规则完全不同。一个拥有数千张显卡的大型集群中,即使只有一张GPU出现所谓的'静默故障'——即设备表面在线但实际性能大幅下降——这种故障就会像病毒一样污染整个训练任务的梯度计算,导致数周的计算资源白白浪费。
这种隐形故障的检测难度极大,因为传统的监控系统往往只能提供宏观层面的集群状态信息,而无法精确到单个训练任务级别的性能分析。当训练过程出现异常时,工程师往往需要花费大量时间进行手动排查,这不仅效率低下,还可能错过最佳的问题发现时机。
GCM工具的核心技术创新
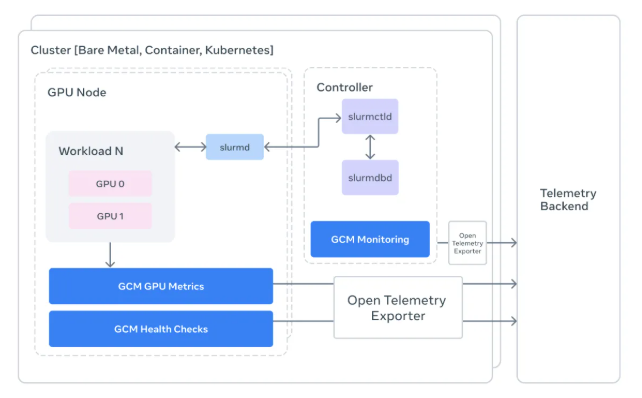
Meta开源的GCM工具包在设计理念上实现了重要突破。该工具的核心价值在于建立了硬件底层遥测数据与上层编排逻辑之间的专业桥梁。通过深度集成业界通用的任务调度器Slurm,GCM实现了前所未有的'任务级'监控能力。
这种监控粒度意味着工程师不再只能看到模糊的集群整体功耗波动,而是能够精准定位到具体是哪个任务ID导致了性能下滑。这种实时的健康地图功能,使得系统能够在研究人员发现问题之前,就自动识别并标记故障节点,从而大大提高了问题响应速度。
前后置检查机制的设计原理
GCM引入的严格'前后置检查'机制是其另一个重要创新。在训练任务开始之前,系统会全面确认网络连接与GPU设备的可达性状态;在任务结束后,则会调用NVIDIA DCGM工具进行深度诊断分析。
这种机制的设计思路类似于航空领域的飞行前检查流程,通过标准化的检查清单确保计算资源处于最佳状态。更重要的是,GCM通过将复杂的底层硬件数据转化为标准化的OpenTelemetry格式,使得运维团队能够像监控网页流量一样,在Grafana等可视化面板上直观地查看GPU的'健康体检报告'。
实际应用场景分析
在实际的大规模AI训练环境中,GCM的应用价值主要体现在三个层面:首先是故障预防,通过持续的健康监测及时发现潜在的硬件问题;其次是资源优化,确保昂贵的计算资源得到最大化利用;最后是训练质量保障,防止有问题的硬件节点影响模型训练效果。
从技术实现角度来看,GCM的成功离不开其对现有生态系统的良好兼容性。工具不仅支持主流的调度系统,还能够与各种监控平台无缝集成,这种设计大大降低了企业的部署门槛。
行业影响与发展前景
GCM的开源发布标志着AI基础设施监控领域的一个重要里程碑。长期以来,大型科技公司在这方面积累了丰富的专有技术,但很少将其开源共享。Meta的这一举动不仅为行业提供了实用的工具解决方案,更重要的是建立了一个可参考的技术标准。
未来,随着AI模型规模的持续扩大,对计算集群稳定性的要求将越来越高。GCM所代表的任务级精细监控理念很可能成为行业标准做法,推动整个AI基础设施领域向更智能化、自动化的方向发展。
从技术演进的角度看,GPU集群监控技术可能会向以下几个方向发展:首先是预测性维护能力的增强,通过机器学习算法提前预测硬件故障;其次是跨平台兼容性的提升,支持更多类型的加速器硬件;最后是自动化修复机制的完善,实现从检测到修复的全流程自动化。
实施建议与最佳实践
对于计划部署类似监控系统的企业,有几个关键因素需要考虑。首先是数据采集的粒度选择,过于细致的数据可能会带来存储和分析压力,而过于粗略的数据又可能无法满足故障诊断需求。其次是报警阈值的设置,需要根据具体的业务场景进行精细化调整。
在实际部署过程中,建议采用渐进式实施策略。可以先在部分集群进行试点,验证监控效果后再逐步推广。同时,需要建立相应的运维流程和应急预案,确保在发现问题时能够快速响应。
从长期来看,成功的监控系统不仅依赖于技术工具,还需要配套的组织架构和人才培养。企业需要培养既懂硬件又懂AI训练的复合型人才,才能充分发挥监控系统的价值。
技术细节深入探讨
在技术实现层面,GCM的成功很大程度上得益于其模块化架构设计。系统各个组件之间采用松耦合方式连接,这使得企业可以根据自身需求选择性地部署特定功能模块。例如,某些场景可能只需要基础的健康监控,而另一些场景则需要完整的性能分析能力。
另一个值得关注的技术细节是数据处理的实时性要求。在大规模集群环境中,监控数据产生的速度极快,如何实现低延迟的数据处理和告警成为技术挑战。GCM通过流式处理架构和分布式计算设计,较好地平衡了实时性与系统资源消耗之间的关系。
从安全角度考虑,监控系统的数据保护同样重要。GCM在设计时考虑了数据加密和访问控制机制,确保敏感的硬件性能数据不会泄露。企业在部署时也需要根据自身的安全要求进行相应的配置调整。
性能优化策略
监控系统本身的资源消耗是需要重点关注的问题。过重的监控可能会影响主业务的性能,而过轻的监控又可能无法达到预期效果。GCM通过智能采样和数据压缩技术,在保证监控效果的同时尽可能降低系统开销。
另一个优化方向是报警机制的智能化。传统的阈值报警容易产生误报或漏报,GCM引入了基于机器学习的异常检测算法,能够更准确地识别真正的异常情况。这种智能报警机制大大减轻了运维人员的工作负担。
从系统可扩展性角度看,GCM的分布式架构设计使其能够支持超大规模集群的监控需求。随着集群规模的扩大,可以通过增加监控节点的方式来保持系统性能,这种设计为未来的扩展留足了空间。
行业标准与生态建设
GCM的开源发布对行业标准的发展产生了积极影响。通过采用OpenTelemetry等开放标准,GCM促进了不同监控工具之间的互操作性。这种开放性有助于构建更健康的生态系统,推动整个行业的技术进步。
从社区建设角度,开源项目的成功离不开活跃的开发者社区。Meta在发布GCM的同时,也提供了详细的文档和示例代码,这有助于降低新用户的使用门槛。随着社区贡献的增加,工具的功能和稳定性都将得到持续改善。
未来,我们可能会看到更多企业基于GCM进行二次开发,满足特定场景的定制化需求。这种开源协作模式将加速技术创新,最终惠及整个AI行业。