技术争议背后的行业现状
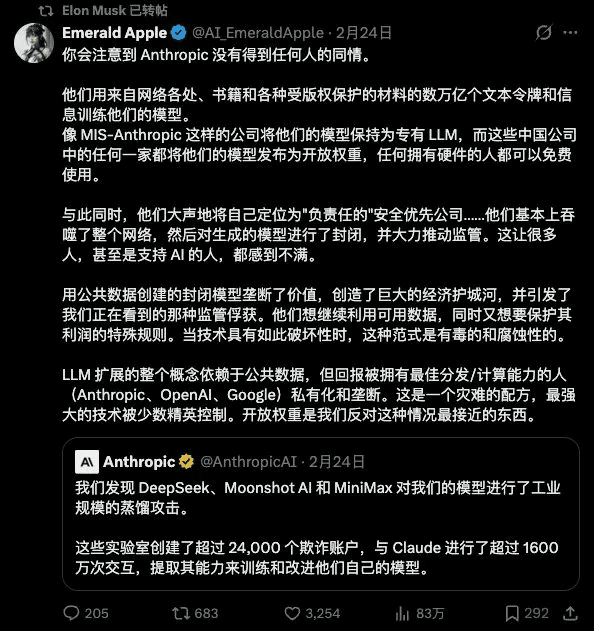
近日,AI行业发生了一起引人注目的事件。Anthropic公司在官方博客中发表声明,指控三家中国AI公司对Claude模型进行了所谓的“工业规模蒸馏攻击”。这一指控迅速在技术社区引发热议,不仅因为其涉及的技术问题,更因为其中体现出的行业双重标准。

蒸馏训练的技术本质
蒸馏训练是机器学习领域的常见技术,其核心思想是通过大型教师模型的输出来训练小型学生模型。这种方法的优势在于能够在保持较高性能的同时,显著降低模型的计算需求和部署成本。从技术层面看,蒸馏过程类似于知识传递,使学生模型能够继承教师模型的部分能力特征。
在实际应用中,蒸馏训练已被广泛采纳。各大科技公司都在使用这一技术来优化模型效率。例如,通过从大型模型蒸馏出轻量级版本,能够在移动设备等资源受限的环境中实现AI功能。这种技术本身并不存在道德或法律问题,关键在于数据获取的合法性和透明度。
行业双重标准的显现
有趣的是,Anthropic此次的指控与其自身的数据使用历史形成了鲜明对比。2025年,该公司因使用盗版网站数据训练模型而支付了15亿美元的和解金。调查显示,Anthropic从LibGen和PiLiMi等盗版网站下载了超过700万本受版权保护的书籍用于模型训练。
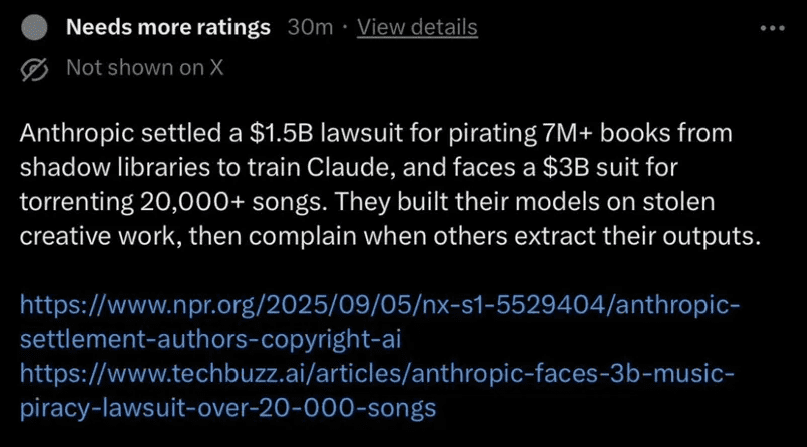
这种“严于律人,宽于待己”的态度引发了技术社区的广泛批评。多位行业专家指出,在AI快速发展的背景下,建立统一、公平的数据使用标准至关重要。如果大型科技公司可以随意使用受版权保护的数据,却对其他公司的类似行为采取不同标准,将不利于行业的健康发展。
知识产权在AI时代的新挑战
AI技术的兴起对传统知识产权制度提出了全新挑战。与物理世界的“偷窃”不同,数据复制并不会导致原数据的消失。这种非竞争性特征使得知识产权保护变得更加复杂。
从历史角度看,每次技术革命都会引发类似的版权争议。印刷术的发明威胁了手抄书行业的生存,录音技术改变了音乐产业的商业模式,互联网的出现重塑了内容分发方式。AI技术作为新一轮技术革命的核心,其与版权制度的冲突在所难免。
构建平衡的创新生态系统
面对这些挑战,需要建立更加细化的数据使用规则。一方面,要保护创作者的合法权益,确保创新得到合理回报;另一方面,也要为技术发展留出足够空间,避免过度保护阻碍进步。
在实践中,可以考虑引入分层的版权管理制度。对于商业性的大规模使用,应当建立明确的授权机制;而对于研究和非商业用途,则可以适当放宽限制。同时,需要建立国际协调机制,防止不同国家间的标准差异导致“监管套利”。
技术伦理与行业自律
AI公司应当加强行业自律,建立透明的数据使用政策。这不仅包括对外部数据的使用规范,也涉及对自身模型输出的管理。通过公开训练数据的来源和处理方式,可以增强公众对AI技术的信任。
此外,行业组织可以发挥更大作用,制定统一的技术伦理标准。这些标准应当涵盖数据采集、模型训练、输出使用等各个环节,为行业发展提供明确指引。同时,建立独立的监督机制,确保标准的有效执行。
全球化视角下的AI治理
在全球化背景下,AI治理需要超越国界思考。不同国家在数据保护、知识产权等方面的法律差异,可能导致监管套利和不公平竞争。因此,建立国际性的AI治理框架显得尤为重要。
这种框架应当尊重各国文化差异,同时确保基本原则的一致性。通过多边合作,可以制定出既保护创新又促进技术传播的平衡方案。特别是在训练数据的使用方面,需要建立国际认可的标准和争议解决机制。
未来展望与建议
随着AI技术的不断发展,相关争议可能会更加频繁。这就要求各方以更加开放和建设性的态度参与讨论。技术公司、政策制定者、学术界和公众需要共同努力,寻找创新与保护之间的平衡点。
具体而言,建议从以下几个方向推进工作:首先,加强技术透明性,让用户能够了解模型的训练过程和数据来源;其次,建立更加灵活的知识产权制度,适应AI时代的特点;最后,促进国际对话与合作,共同应对全球性挑战。
通过这些努力,可以为AI技术的健康发展创造更加有利的环境,确保技术进步能够惠及全社会。在这个过程中,避免双重标准和促进公平竞争将是关键所在。