随着大语言模型规模的不断扩大和预训练强度的持续提升,强化学习在后训练阶段的作用正在引发深入讨论。当前学术界存在一个核心争议:强化学习究竟是真正教会模型新能力,还是仅仅对模型内部已有解法进行筛选和重排?

实验设计的创新之处
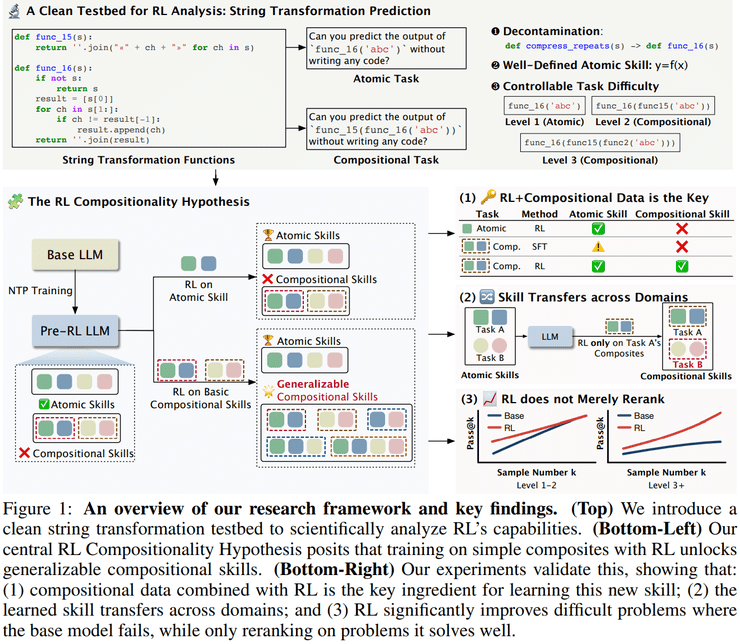
为了回答这一根本性问题,研究团队选择退回到高度可控的实验环境。他们设计了20余个随机命名的字符串操作函数,这些函数采用无意义字符串命名,有效排除了预训练语料污染和模型语义联想的影响。这种设计确保了模型必须真正理解函数逻辑,而非依赖名称猜测。
实验核心在于对比两种能力:原子能力和组合能力。原子能力指模型在不依赖提示中函数定义的情况下准确预测单一函数输出的能力;组合能力则指模型预测多层复合函数执行结果的能力。通过这种明确的定义,研究人员能够精确量化模型的能力变化。
两阶段训练流程的设计
研究采用了两阶段训练设计,刻意将"掌握单个技能"和"学会组合技能"分离。第一阶段使用监督学习训练模型掌握每个字符串变换函数的具体行为,建立稳定的原子技能基础。第二阶段完全隐藏函数定义,仅向模型提供函数名称和输入字符串,迫使模型真正理解并组合已掌握的原子技能。
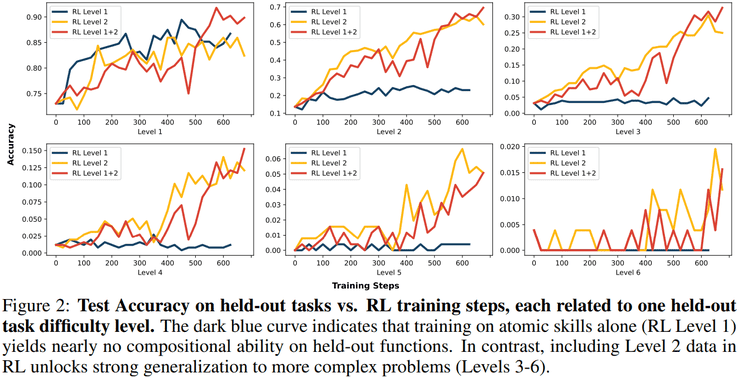
在第二阶段中,研究人员系统比较了监督学习和强化学习两种训练方式。结果显示,仅在单函数上进行强化学习的模型,在更深层次组合任务上的准确率几乎为零。而一旦训练数据中包含基础的二层嵌套函数,模型在三层组合上的准确率可提升至约30%,在四层组合上仍保持约15%,并在更高层级上持续显著优于随机水平。
组合能力的泛化特性
更令人印象深刻的是,这种组合能力展现出跨任务迁移的特性。研究发现,如果模型在A、B任务上学习了原子能力,仅在A任务上进行合适的组合能力强化学习,模型就能将该能力泛化至B任务上。这表明强化学习获得的并非特定于字符串任务的技巧,而是一种能够组织和调度已有原子技能的通用能力。
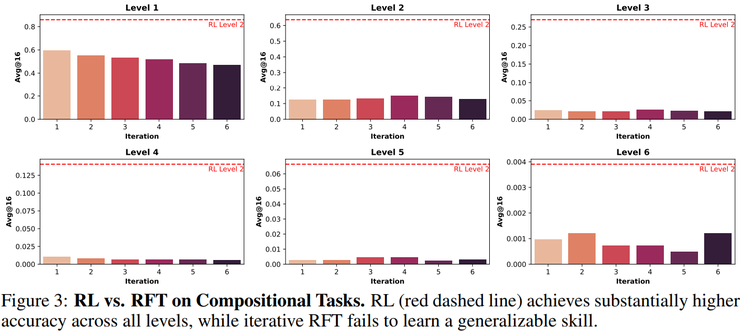
然而,这种迁移是有条件的。研究显示,在其他任务上学到的组合能力并不能泛化到模型不具备原子能力的任务上。这意味着强化学习教会模型的是一种元技能,但这种元技能的发挥需要建立在扎实的原子能力基础之上。
对"强化学习只是重排"观点的回应
针对"强化学习只是将pass@k压缩为pass@1"的观点,研究人员进行了深入分析。发现在低难度任务上,基础模型确实能够通过多次采样得到正确答案,强化学习的作用主要体现为重排。但在高难度组合任务中,基础模型即使在极大采样预算下仍表现不佳,而强化学习模型的优势随着采样数增加不断扩大。
这种差异表明,"强化学习只是重排"的结论在一定程度上是一种评测假象。当任务复杂度超过某个阈值时,强化学习确实能够带来本质性的能力提升。
错误类型分析的启示
错误类型分析进一步揭示了强化学习带来的根本性变化。基础模型、监督学习模型以及仅进行原子强化学习训练的模型,其主要错误来源于忽略组合结构或误解嵌套关系。而经过组合任务强化学习训练的模型,其错误更多来自原子步骤的执行失误,而非对整体组合结构的误解。
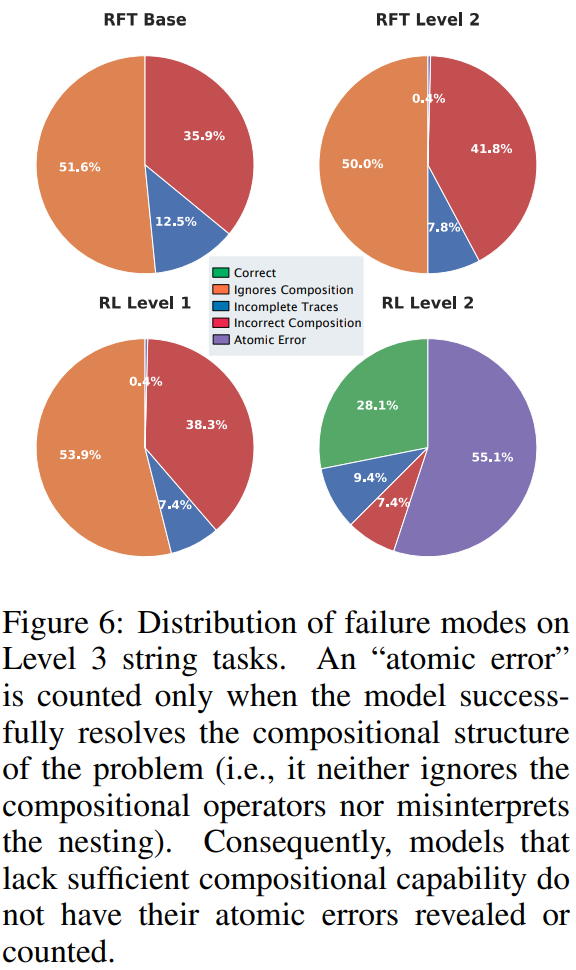
这一发现表明,强化学习首先教会模型正确理解和执行组合结构。即使失败,也失败在更低层级,体现出认知层面的结构性变化。这种变化不仅体现在准确率指标上,更体现在模型内部推理过程的根本性重组。
研究方法论的创新价值
这项研究的方法论创新值得重点关注。通过选择字符串变换函数作为研究载体,研究人员成功构建了一个行为完全确定、复杂度可严格控制的环境。这使得"新技能"不再是抽象概念,而成为可以被精确检验和逐层分析的研究对象。
在评测方法上,研究团队没有依赖单一的整体指标,而是从多个维度构建完整证据链。他们通过测试新函数的组合能力排除简单记忆的可能,通过更深层次的函数嵌套考察模型是否形成可泛化的组合策略,并通过跨任务迁移实验检验能力的通用性。
对实际应用的启示
这项研究对大语言模型的实际训练具有重要指导意义。它提示我们,预训练或监督微调阶段的核心作用在于帮助模型掌握基本操作和原子能力,而强化学习更适合用于学习如何组织和调度这些已有能力。这种分工思路与人类技能学习理论高度一致。
在实际应用中,这意味着我们需要更加重视原子能力的培养。只有当模型具备扎实的基础技能时,强化学习才能最大程度地发挥其促进组合能力形成的作用。同时,训练任务的设计需要能够真实激励模型去使用和发展新能力。
未来研究方向
基于这项研究的发现,未来有几个值得深入探索的方向。首先是探索更复杂的组合模式,如条件组合、循环组合等。其次是研究不同奖励函数设计对组合能力形成的影响。此外,将这种方法论扩展到自然语言任务中,验证其在更复杂场景下的适用性也是重要方向。
另一个有趣的方向是研究组合能力的遗忘特性。模型学会的组合能力是否会随着时间推移而衰减?如果需要保持这种能力,需要什么样的持续训练策略?这些问题都对实际应用具有重要价值。
结语
这项研究为我们理解强化学习在大模型能力培养中的作用提供了新的视角。它表明,在合适的条件下,强化学习确实能够促使模型获得真正的新能力,而不仅仅是对已有能力的重排。这种能力的本质是一种系统性的技能组合策略,具有可泛化和可迁移的特性。
这项研究的价值不仅在于其具体实验结果,更在于其建立的可控实验范式和分析框架。它为后续研究提供了可复现的方法论基础,推动相关讨论从模糊的概念争论转向精确的实证分析。随着大模型技术的不断发展,这种严谨的研究方法将变得越来越重要。