在人工智能向专业领域纵深发展的进程中,运筹优化建模的可靠性问题长期困扰学术界。上海交通大学智能计算研究院团队在ICLR 2026发表的研究成果,通过创新性框架设计为这一难题提供系统性解决方案。
传统运筹建模方法存在两大根本缺陷:其一是结果导向奖励导致的信用分配失真,模型可能因最终答案正确而固化错误的建模逻辑;其二是局部过程监督的短视性,难以捕捉步骤间的强耦合关系。这导致即使生成错误的数学模型,只要求解结果正确仍会被强化,埋下重大应用隐患。
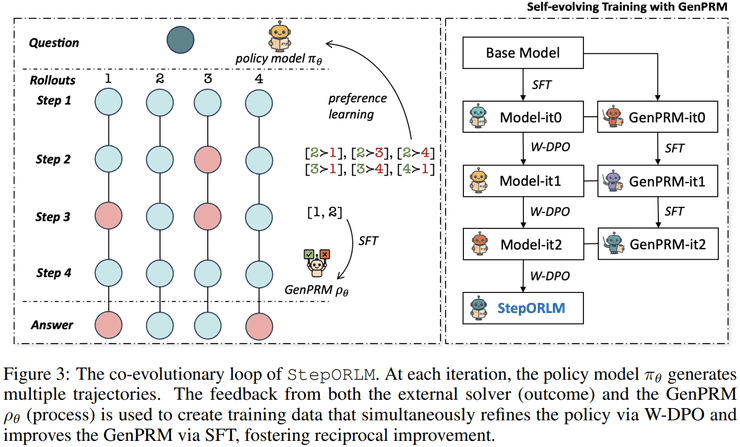
StepORLM框架采用双阶段训练策略实现范式突破。第一阶段通过教师模型构建高质量初始数据集,涵盖变量定义、约束设计等完整建模流程。第二阶段创新性引入生成式过程奖励模型(GenPRM),通过全局回顾式评估建立正反馈闭环。该模型不局限于单步判断,而是具备跨步骤推理能力,能识别早期决策对整体建模的影响。
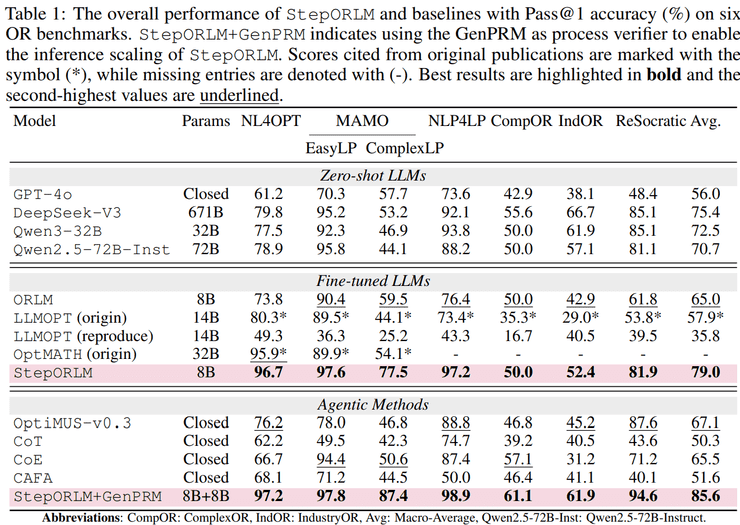
实验验证显示该框架的显著优势:
- 在IndustryOR数据集实现85.6%的Pass@1准确率
- 相比GPT-4o零样本表现提升23.7%
- 消融实验表明自进化机制使性能随迭代持续累积
- GenPRM验证器可迁移至其他模型提升近10%性能
该研究的理论价值在于重新定义了复杂推理任务的监督方式。通过构建具备推理能力的奖励模型,实现从"局部正确"到"全局一致"的认知跃迁。在工业应用场景中,这种能力尤为重要——例如供应链优化时漏掉运输约束可能短期不影响成本,但会引发长期系统性风险。
技术实现层面,StepORLM采用加权DPO算法区分错误严重程度。在ComplexOR任务中,模型能自动识别变量定义模糊等隐性错误,这在传统监督模式下极易被忽略。通过将建模过程分解为可验证的逻辑单元,系统实现了数学严谨性与工程实用性的平衡。
这项突破对AI应用具有广泛启示:在数学证明、科学建模等长链条任务中,监督信号的设计需要超越结果导向思维。研究团队提出的全局过程监督思想,为构建可信赖的AI系统提供了新方法论。随着该框架的开源,其影响力有望扩展到金融风控、能源调度等更多高价值领域。
当前研究仍存在改进空间:在超大规模非线性规划问题上,模型收敛速度仍有待提升。团队下一步计划将框架扩展到多目标优化场景,并探索与量子计算的结合可能性。这项工作标志着AI运筹学研究从"解题工具"向"建模专家"的范式转变,为智能决策系统的落地应用扫除关键障碍。