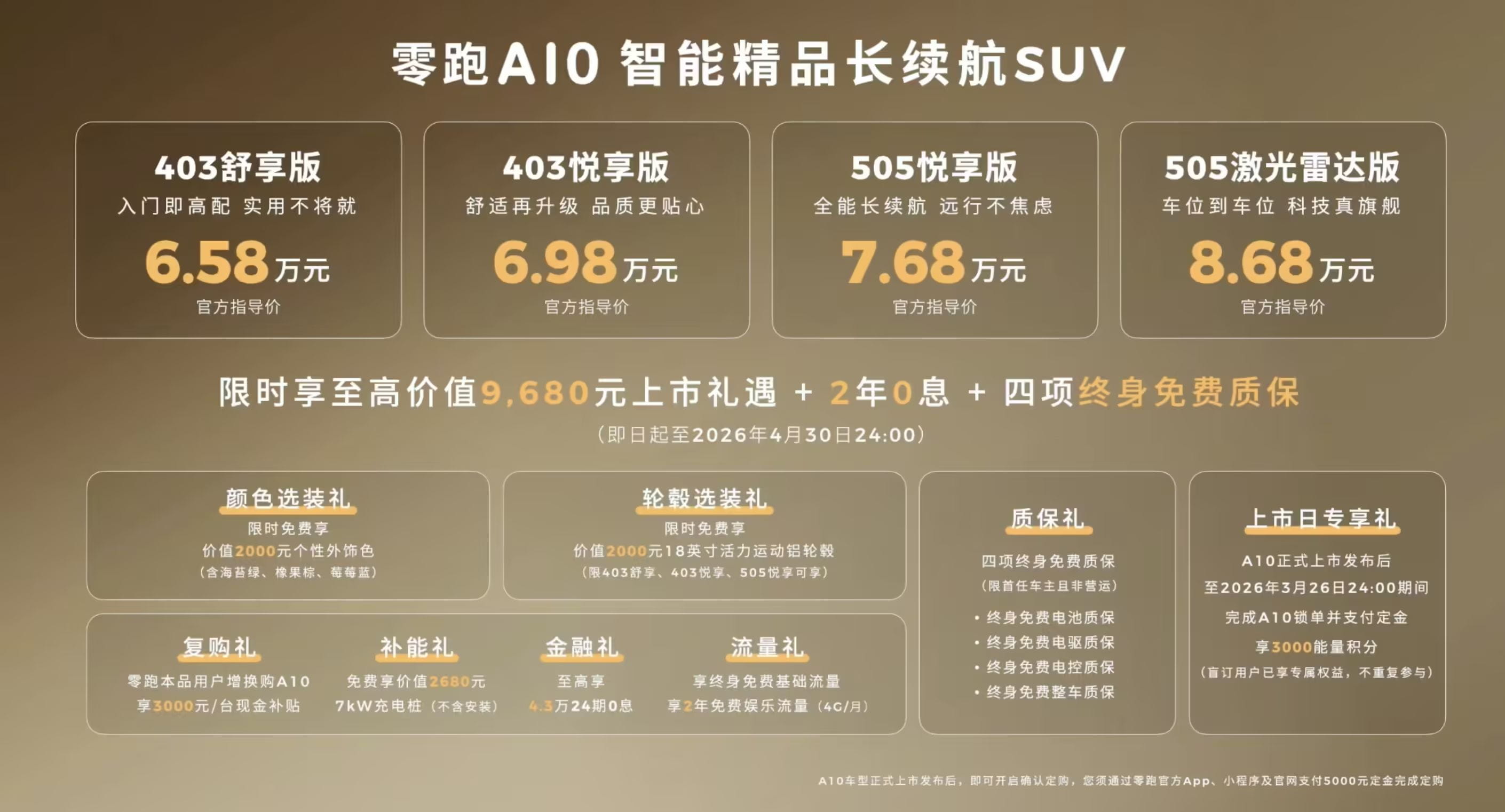
在文档数字化需求呈指数级增长的当下,DeepSeek团队推出的DeepSeek-OCR 2凭借其突破性架构,重新定义了OCR技术的边界。该模型通过创新的视觉处理机制,在保持高精度识别的同时,实现了对复杂文档结构的语义级理解。
技术架构革新
DeepEncoder V2架构采用分层处理机制,首先通过SAM-base视觉分词器将图像离散化为视觉Token,配合两层卷积网络输出896维特征向量。与传统固定扫描方式不同,其核心创新在于因果流查询(causal flow queries)机制,该机制允许模型根据上下文语义动态调整视觉Token的处理顺序。
在具体实现中,视觉Token使用双向注意力机制捕捉全局特征,而因果流查询则采用单向注意力模式,这种双流注意力架构有效平衡了计算效率与识别精度。测试显示,该架构仅需256-1120个视觉Token即可完整解析复杂页面,计算开销降低40%以上。
训练体系优化
模型采用三阶段训练流程:
- 编码器预训练:在百万级文档图像数据集上进行基础特征学习
- 查询增强阶段:通过对比学习强化因果流查询的语义关联性
- 解码器专门化:基于DeepSeek-MoE Decoder(30亿参数)进行任务适配
这种渐进式训练策略使模型在OmniDocBench v1.5测试中达到91.09%的综合得分,特别是在阅读顺序识别任务中,错误率降低62%。解码器部分采用混合专家系统(MoE),实际推理时仅激活约5亿参数,显著提升处理效率。
应用场景拓展
在实际应用中,该模型展现出多维度的技术优势:
- 学术文献处理:可精准解析包含复杂数学公式的PDF文档,支持LaTeX代码自动生成
- 企业合同分析:自动识别多栏布局中的关键条款,支持法律文本的结构化提取
- 教育领域应用:智能识别手写批注与印刷文本的混合内容,实现试卷的数字化归档
- 出版行业适配:有效处理多语种排版,支持复杂文字流的还原
测试数据显示,对于包含表格、公式、图表的混合文档,模型处理速度较前代提升3.2倍,同时将重复识别率控制在0.7%以下。这种性能提升使其在大规模数字化项目中展现出显著优势。
技术发展趋势
该模型的推出标志着OCR技术正从单纯的字符识别向语义理解演进。其动态重排机制为处理非结构化文档提供了新思路,未来可能催生更多基于视觉语义的文档分析应用。值得注意的是,该技术与大语言模型的结合,或将推动文档处理进入真正的智能化时代。
目前,研究团队已开源完整模型架构,开发者可通过GitHub仓库获取训练代码和预训练权重。这种开放策略有望加速技术迭代,推动OCR技术在医疗记录、历史文献保护等领域的深度应用。