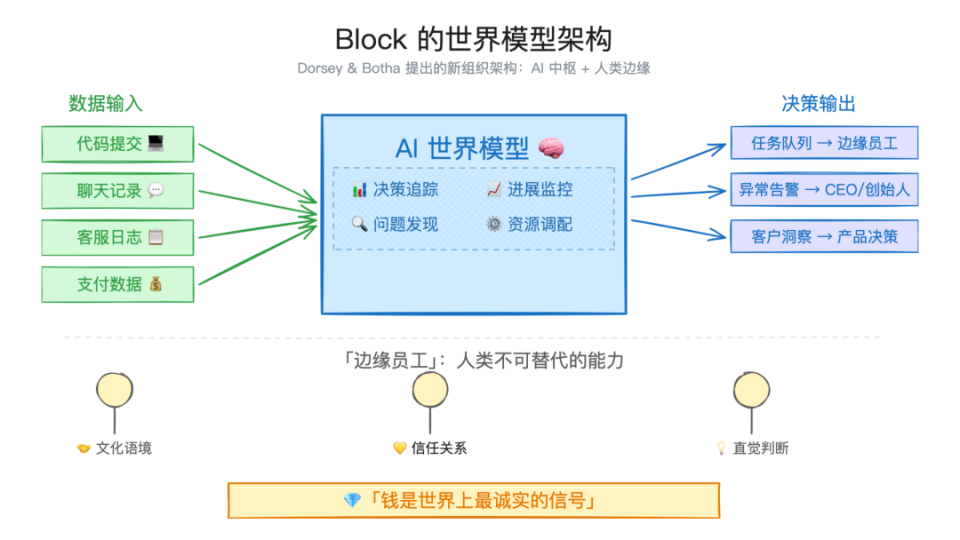
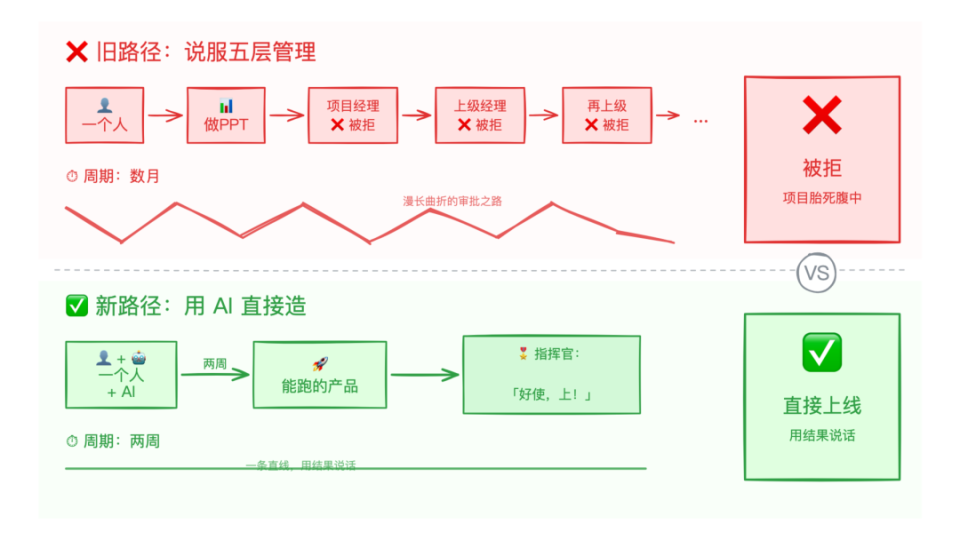
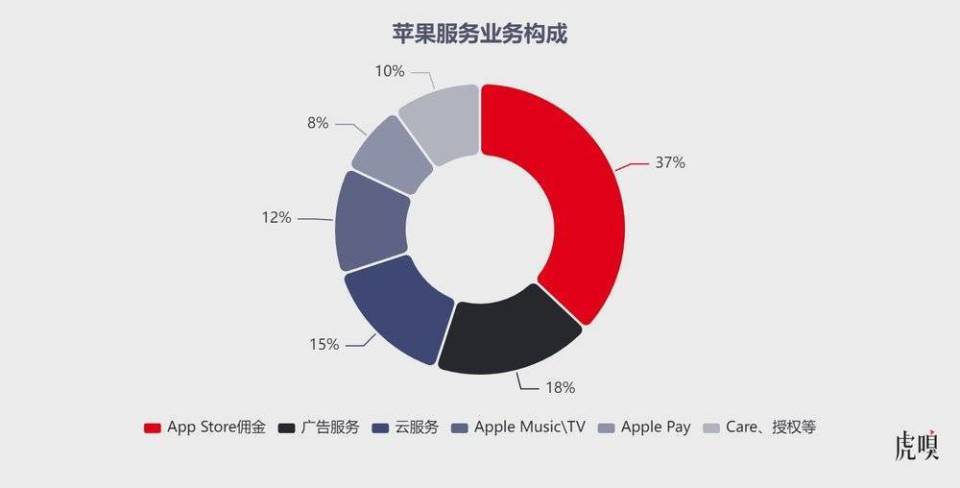
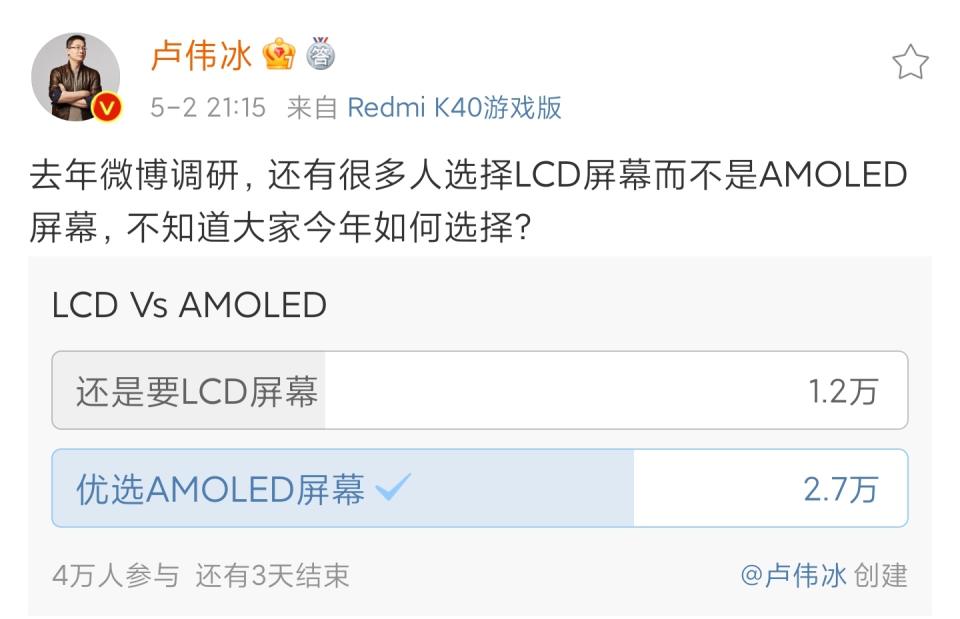
2025年初,一款名为DeepSeek-R1的开源大模型横空出世,其在大洋彼岸的下载排名甚至超越了ChatGPT,标志着中国AI力量首次站上全球舞台中央。时值DeepSeek出圈一周年,这个由量化基金公司幻方量化孵化的技术奇迹,正在经历从黑马到行业标杆的关键转型期。
算力神话的终结与新竞争维度
曾几何时,万亿参数和天价训练成本被视为大模型能力的黄金标准。OpenAI、谷歌等巨头持续加码算力投入,微软计划未来五年投入数千亿美元构建AI基础设施。DeepSeek-R1的出现彻底颠覆了这一认知:其总训练时长仅80小时,成本控制在29.4万美元,却在多项基准测试中达到顶尖水平。
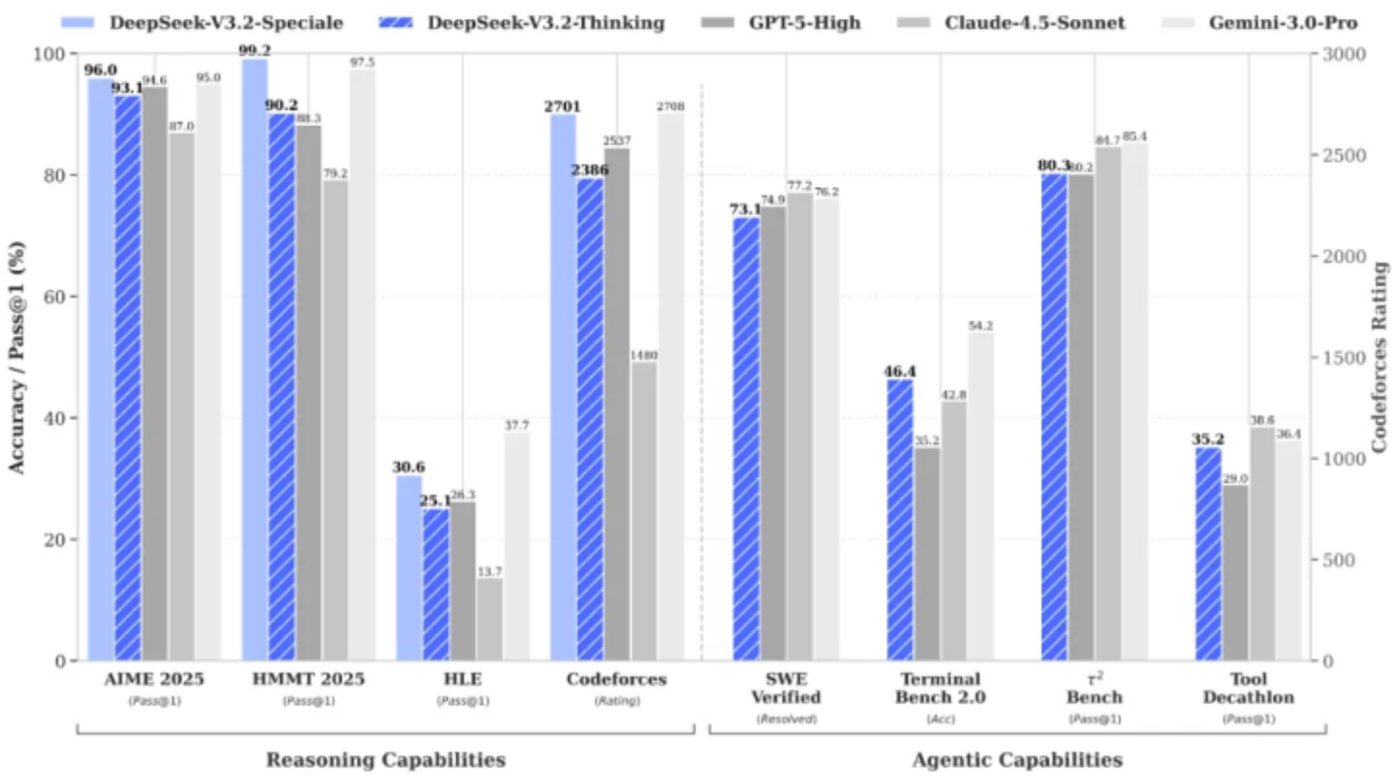
DeepSeek V3.2在推理类测试中全面对标GPT-5
这种「小模型大智慧」的技术路径引发行业地震。2025年第三季度数据显示,采用精简架构的开源模型占比从年初的32%飙升至78%,参数过千亿的新模型发布量同比下降40%。这标志着一个根本性转变:模型效率正取代算力规模成为核心竞争力。黄仁勋在GTC大会上特别指出:「DeepSeek-R1让世界看到,模型优化比单纯堆砌GPU更具商业穿透力。」
开源生态的重构与挑战
DeepSeek的成功引爆了开源模型的商业价值想象。其建立的「基础模型+生态赋能」模式,吸引腾讯云、阿里云等十余家云服务商接入,形成覆盖2亿开发者的技术网络。据《2025全球AI生态报告》,基于DeepSeek衍生的行业模型超过17万个,较2024年增长15倍。
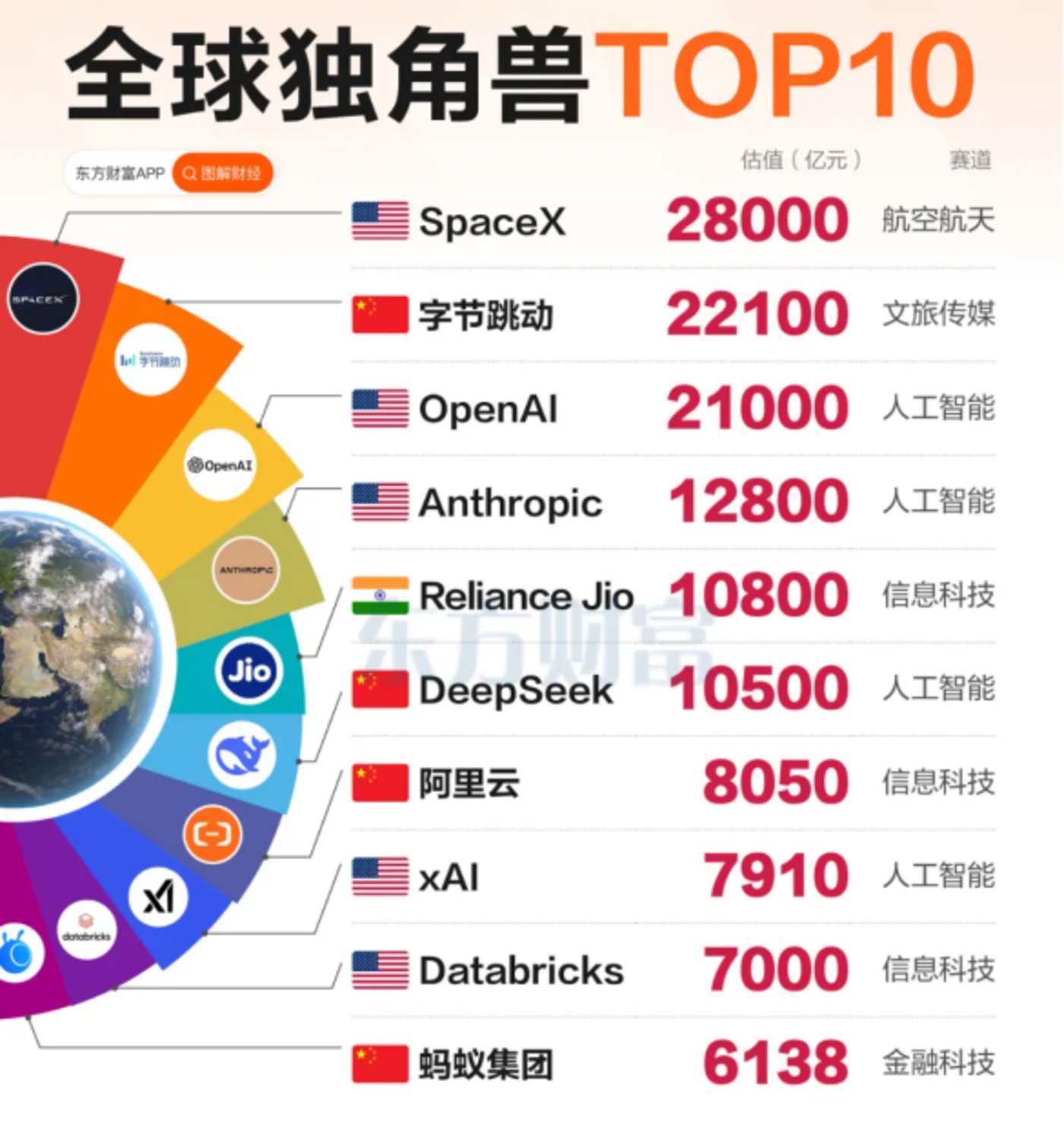
DeepSeek以1.05万亿估值位居全球独角兽第四
然而这种先发优势正遭遇严峻挑战:
- 巨头觉醒:阿里开源300余个垂直领域模型,百度开放文心一言90%核心能力
- 垂直切割:九坤投资发布编程专用模型IQuest-Coder-V1,直指DeepSeek V4的工程师群体
- 人才争夺:OpenAI挖角幻方核心算法团队,Anthropic设立上海研究中心
更值得警惕的是用户生态的变化。QuestMobile 2025Q3报告显示,DeepSeek月活用户较峰值下降25%,流失用户主要转向豆包、文心一言等应用。
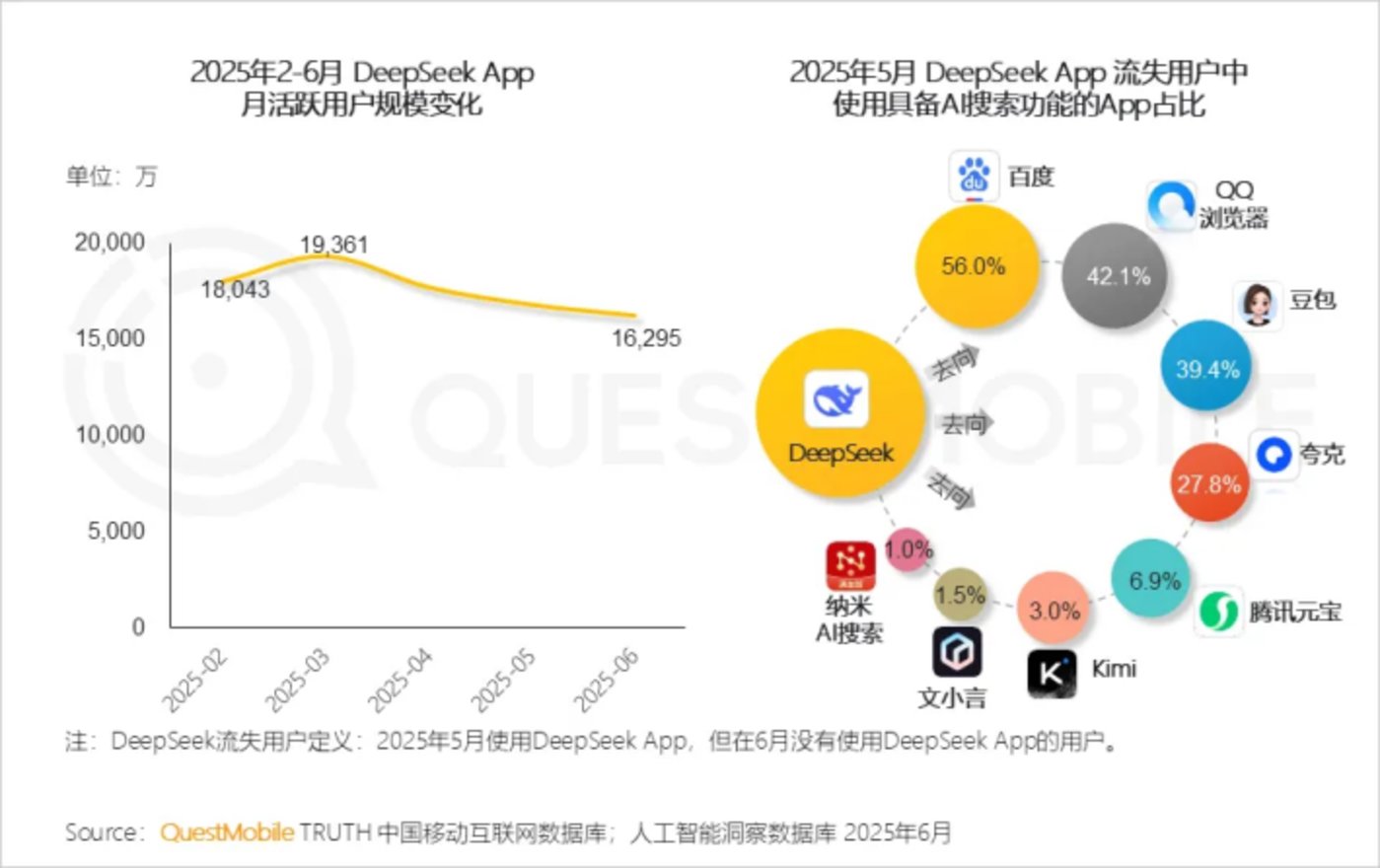
DeepSeek用户流失分布图
应用场景的争夺与战略选择
当行业共识转向「大模型的终点是应用」,DeepSeek面临着关键战略抉择。创始人梁文锋多次强调「不做终端应用,专注基础创新」的定位,这与互联网大厂的路径形成鲜明对比。
这种错位竞争在短期内避免了正面冲突,但也导致在消费端战场逐渐失守。教育、医疗、金融等垂直领域的数据显示,使用DeepSeek作为底层引擎的第三方应用,用户留存率比直接竞品低18个百分点。资深AI产品经理李明浩分析:「技术优势需要转化为用户体验,DeepSeek的API模式在响应速度、界面友好度上仍存差距。」
幻方量化提供的资金后盾是把双刃剑。2025年幻方以56.6%收益率位列百亿私募榜眼,为DeepSeek提供持续研发保障。但量化基金「零和博弈」的属性,也引发部分投资者对DeepSeek商业伦理的质疑。
DeepSeek公开的技术演进路线
通往2026年的关键战役
面对即将发布的V4模型,DeepSeek需要破解三重悖论:
- 开源与商业化的平衡:如何在不损害社区热情的前提下建立可持续商业模式
- 广度与深度的取舍:通用能力提升与垂直领域精专如何资源配置
- 技术理想与市场现实的磨合:工程师文化主导的团队如何应对消费级市场需求
行业观察家指出,DeepSeek真正的对手不是某个具体玩家,而是时间窗口。随着多模态大模型、神经符号系统等新技术路线崛起,当前基于Transformer的架构优势可能在未来18-24个月内衰减。中国人工智能学会秘书长王海峰认为:「下一阶段竞争焦点将从模型能力转向生态健康度,包括开发者活跃度、企业采用率、学术影响力等综合指标。」
在AI马拉松的赛道上,DeepSeek已证明自己拥有颠覆规则的实力。当开源之光从技术理想照进商业现实,这个一岁的「颠覆者」需要学会在变与不变中寻找新的平衡点——这或许比创造下一个性能奇迹更具历史意义。