重新定义语言模型的记忆范式
在现有Transformer架构中,大型语言模型主要依赖混合专家(MoE)系统实现条件计算,却缺乏原生的知识检索机制。DeepSeek团队提出的Engram模块创造性地构建了独立的条件记忆维度,通过现代版N-gram嵌入技术实现O(1)时间复杂度的知识查找。这种结构化分离使模型能够将局部模式重建任务从浅层网络中剥离,从而释放深层网络的复杂推理能力。

双阶段执行机制
Engram模块在序列处理的每个位置依次执行检索与融合两个阶段:
- 稀疏检索阶段:通过词表投影压缩技术将128k词表缩减23%,生成规范化标识符后采用多头哈希机制。每个N-gram阶数配备K个独立哈希头,有效解决哈希冲突问题。
- 动态融合阶段:检索得到的静态嵌入经过上下文感知门控调整,其设计灵感源于注意力机制。通过轻量级卷积精炼后,最终与Transformer主干的多分支架构集成。
系统层面的创新突破
计算存储解耦架构
Engram的确定性检索特性支持独特的系统优化策略。与MoE依赖运行时路由不同,其检索索引完全由输入序列决定:
1. 训练阶段:采用模型并行方案,通过All-to-All通信实现嵌入表分片
2. 推理阶段:实施预取-重叠策略,利用PCIe从主机内存异步预取
3. 层级协同设计:在满足建模需求前提下,选择最优插入位置缓冲通信延迟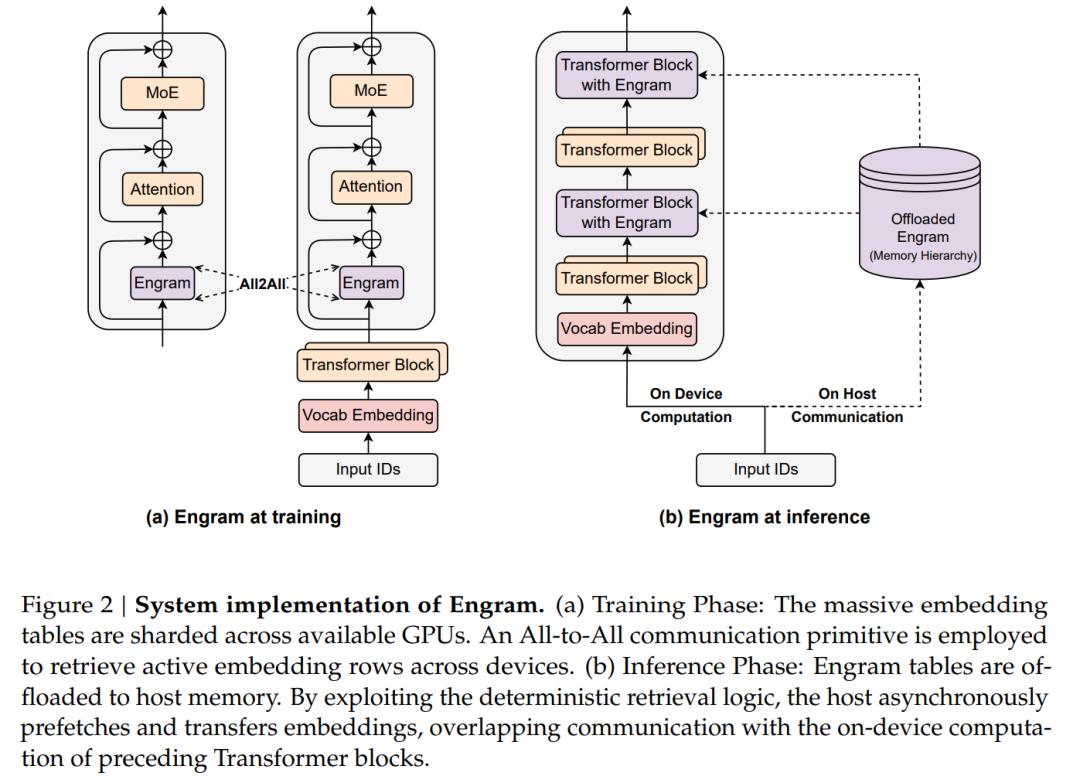
多级缓存层次结构
基于语言N-gram的Zipfian分布特性,建立三级缓存体系:
- 高频嵌入缓存于GPU HBM
- 中频数据存放主机DRAM
- 低频长尾模式存储于NVMe SSD 这种设计使Engram在扩展至亿级参数规模时,仍保持亚毫秒级访问延迟。
揭示U型扩展规律
稀疏性分配问题
在总参数量(P_tot)和激活参数量(P_act)固定的约束下,研究团队定义了关键度量指标:
- $P_{sparse}$ = P_tot - P_act(未激活参数预算)
- $\rho$ = P_moe / (P_moe + P_engram)(MoE分配比例)
通过270亿参数规模的对照实验,发现当$\rho$降至40%时(即MoE专家数减少40%),Engram模型仍能保持基准性能。而最优分配点出现在$\rho$=75%-80%区间,此时验证损失改善0.0139(10B规模)。
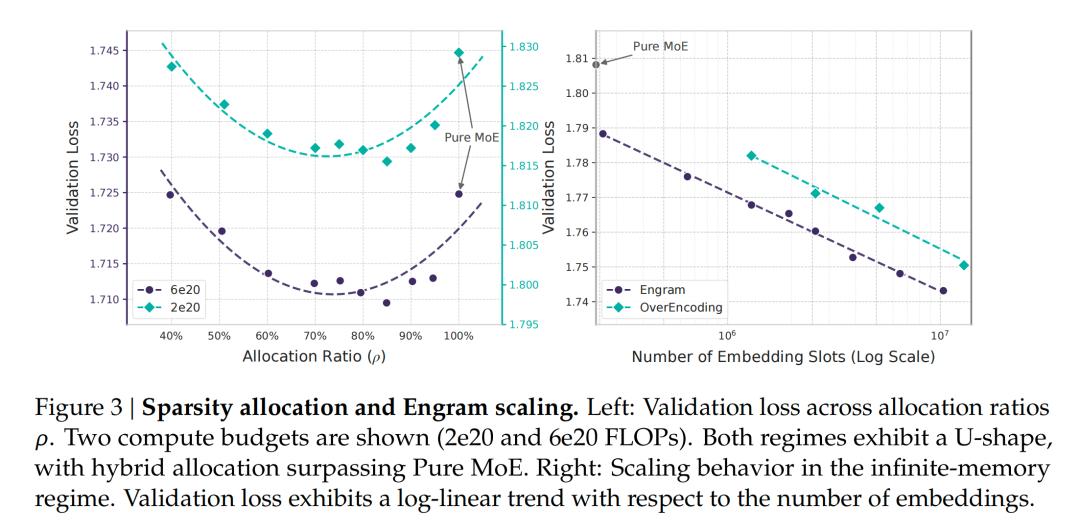
无限记忆范式验证
在固定MoE主干(P_tot≈3B)基础上扩展Engram槽位:
- 槽位数从2.58×10⁵增至1.0×10⁷
- 验证损失呈现严格幂律下降
- 相同内存预算下,Engram比OverEncoding释放更大扩展潜力
实证性能突破
预训练基准测试
在2620亿token语料上训练四类模型对比:
| 模型类型 | 总参数 | MMLU提升 | BBH提升 | HumanEval提升 |
|---|---|---|---|---|
| Dense-4B | 4.1B | 基准 | 基准 | 基准 |
| MoE-27B | 26.7B | +0.0 | +0.0 | +0.0 |
| Engram-27B | 26.7B | +3.0 | +5.0 | +3.0 |
| Engram-40B | 39.5B | +3.2 | +5.3 | +3.4 |
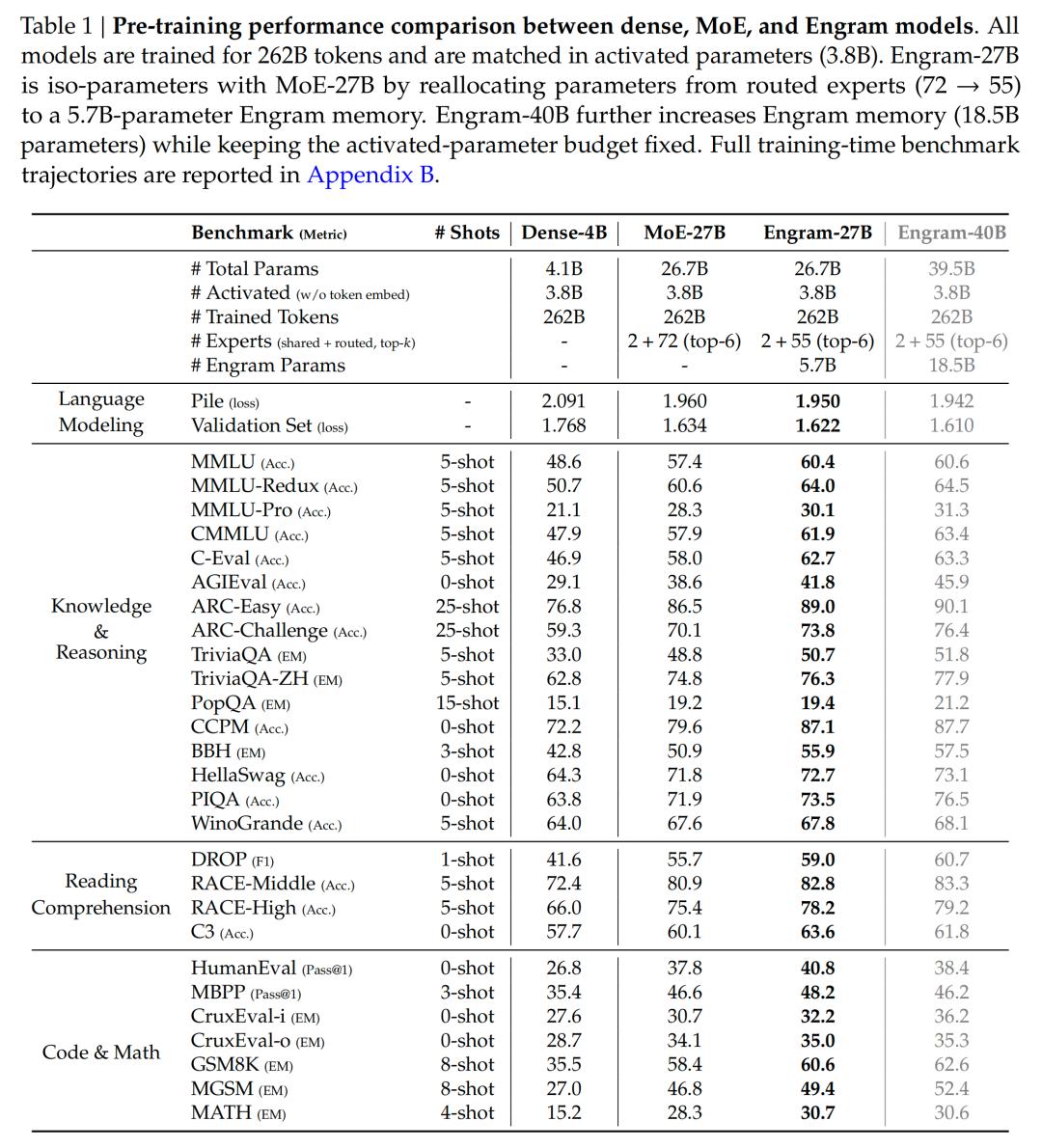
值得注意的是,Engram-27B在知识任务(CMMLU +4.0)、数学推理(MATH +2.4)等领域均展现超线性提升。这种增益源于模块对网络有效深度的重构:LogitLens分析显示,Engram使浅层网络的KL散度降低37%,相当于增加4个等效计算层。
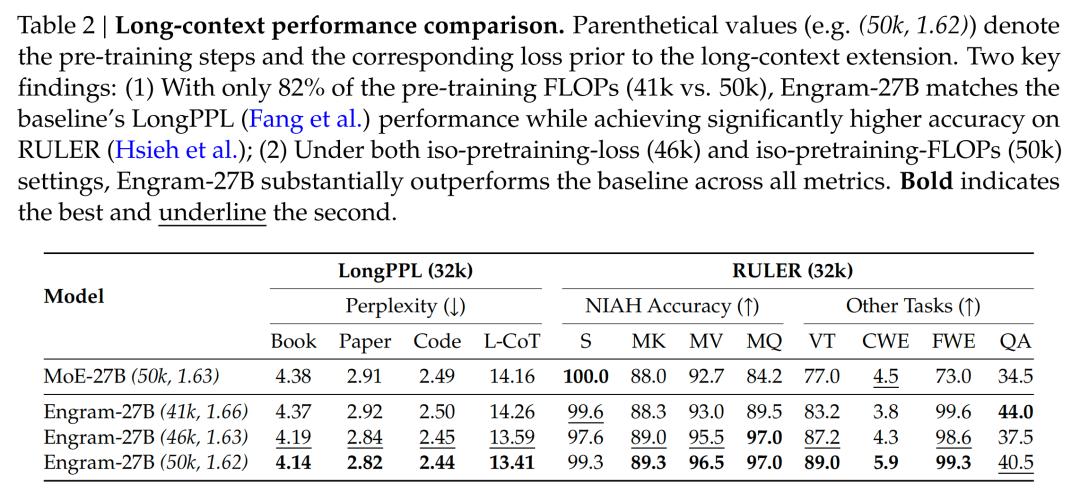
长上下文处理革命
通过等损失对照实验(控制基础模型能力相同):
- 多查询NIAH准确率:97.0 vs 基准84.2
- 变量跟踪(VT)准确率:87.2 vs 基准77.0
- 128K上下文perplexity降低15%这种跃升源于注意力机制的容量释放:当局部依赖交由查表机制处理后,注意力头可专注于全局关联建模。在RULER基准测试中,Engram以82%的计算量达到基准模型100%的性能水平。
架构影响的深度解析
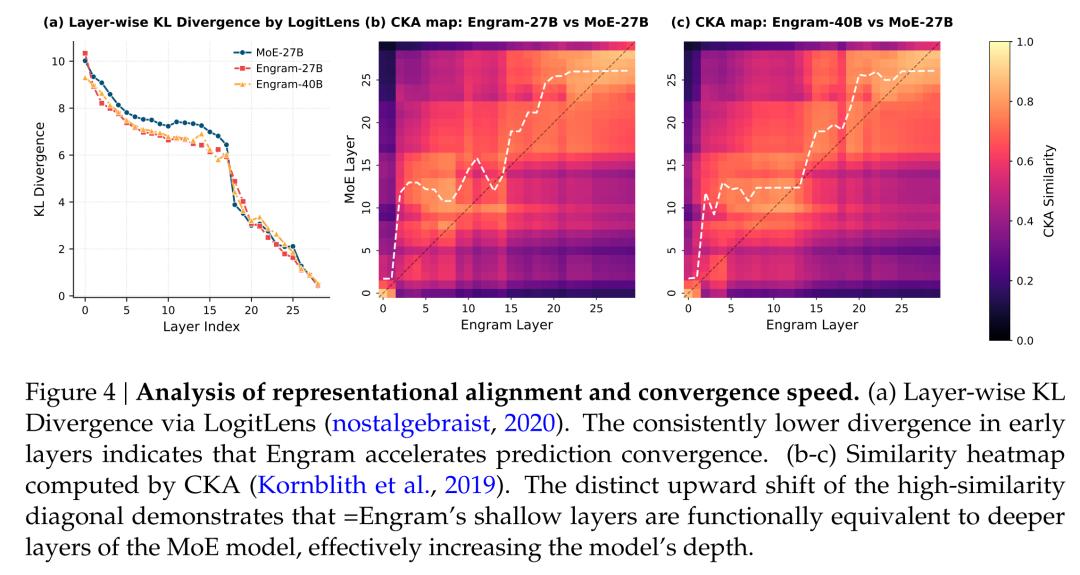
表示对齐加速收敛
通过CKA(Centered Kernel Alignment)相似度热力图分析:
- Engram模型第8层与MoE模型第12层的功能相似度达0.91
- 前6层相似度对角线显著上移,证明静态记忆模块实现深度等效
- 训练收敛速度提升40%,尤其在复杂推理任务中更为显著
产业应用前瞻
Engram架构为解决大模型部署痛点提供新思路:
- 边缘计算场景:通过主机内存预取机制,在移动设备实现大容量知识库调用
- 多模态扩展:静态记忆槽可存储跨模态特征嵌入,为视觉-语言对齐提供基础设施
- 持续学习框架:解耦设计支持动态更新记忆表而无需重训主干网络 当前实验显示,当Engram记忆槽扩展至千亿规模时,在专业领域知识测试中呈现对数级性能增长。这种可预测的扩展特性,使其成为构建领域专用大模型的核心组件。