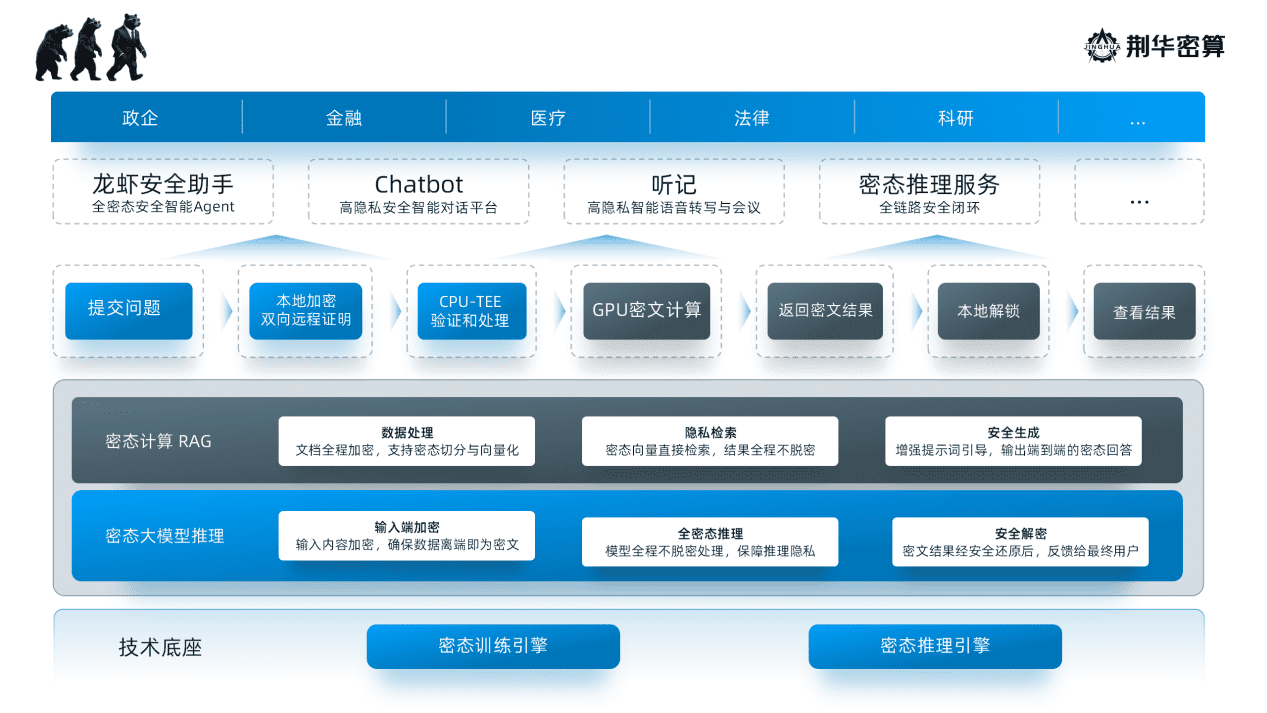
突破网络瓶颈的镜像加速方案
中小型团队部署AI服务时,跨境网络延迟常导致依赖安装失败。清华大学开源软件镜像站(TUNA)通过阿里云CDN实现热门Python包的本地化缓存,实测下载速度从1-3MB/s提升至40MB/s以上,首字节响应时间低于20ms。这种优化源于TUNA的全量元数据同步机制,相比简单反向代理显著提高了并发稳定性。
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/容器化构建标准化环境
将镜像源配置嵌入Dockerfile可创建可复用的基础镜像:
FROM python:3.10-slim
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
RUN pip install tensorflow==2.13.0 numpy protobuf该方案使后续节点扩容时间从小时级缩短至分钟级,且完全规避了外网依赖风险。经测试,91节点集群的初始化时间从传统方案的3天压缩至2小时。
轻量化推理引擎实现
通过分离训练与推理环节,采用TensorFlow SavedModel格式导出模型:
model.save('saved_models/image_classifier')部署时仅需加载推理引擎:
docker run -p 8501:8501 \
--mount type=bind,source=./saved_models,target=/models \
tensorflow/serving此方案剥离了Keras等训练组件,使单个服务实例内存占用降至800MB以下。MobileNetV2模型实测显示,CPU推理完全满足边缘场景需求。
规模化部署的工程实践
依赖版本精确控制
未锁定版本曾导致集群混用TensorFlow 2.13和2.14rc版,引发序列化错误。必须严格约束requirements.txt:
tensorflow==2.13.0
numpy==1.24.3
protobuf==3.20.3分批次滚动更新
91节点并发下载仍可能压垮内网带宽,采用Ansible分批次部署:
for i in {0..90..10}; do
ansible-playbook deploy.yml --limit "nodes[$i-$((i+9))]"
sleep 30
done私有缓存增强鲁棒性
在中心节点搭建Nexus私有仓库缓存常用AI包,使外部依赖请求量减少95%。结合Harbor构建完整的私有镜像生态,彻底实现离线部署。
全链路监控体系
部署完成后必须建立监控基线:
- Prometheus实时采集节点资源指标
- cAdvisor追踪容器运行状态
- 业务级埋点统计QPS与延迟
start = time.time()
result = model(input_data)
metrics.record_latency(time.time() - start)
平民化AI落地方案
该架构的核心创新在于:通过本地化加速解决网络瓶颈(带宽提升40倍),标准化镜像保证环境一致性(构建时间减少90%),轻量化部署降低资源消耗(内存节省70%)。这种模式特别适合高校实验室教学演示,某课程项目成功在50节点集群运行实时目标检测服务。
随着TUNA等公益项目持续完善,国内AI基础设施正从“可用”向“好用”跃迁。技术民主化的本质不是降低门槛,而是重建公平的起跑线——当91个节点也能流畅跑AI时,创新才能真正遍地开花。