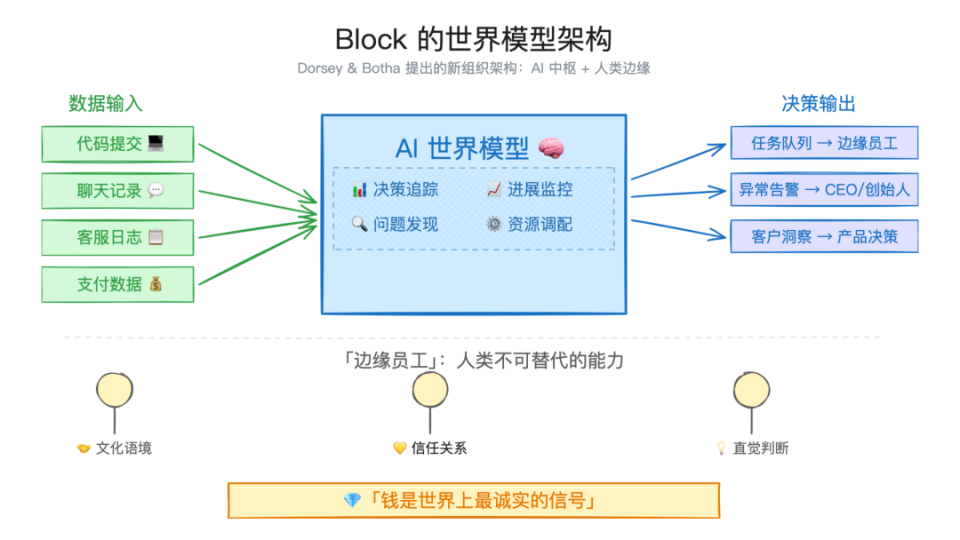
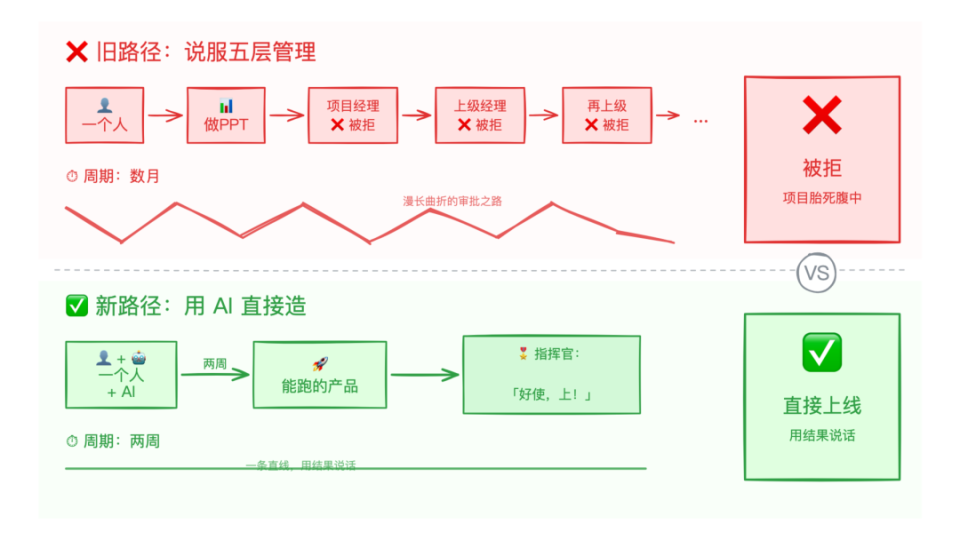
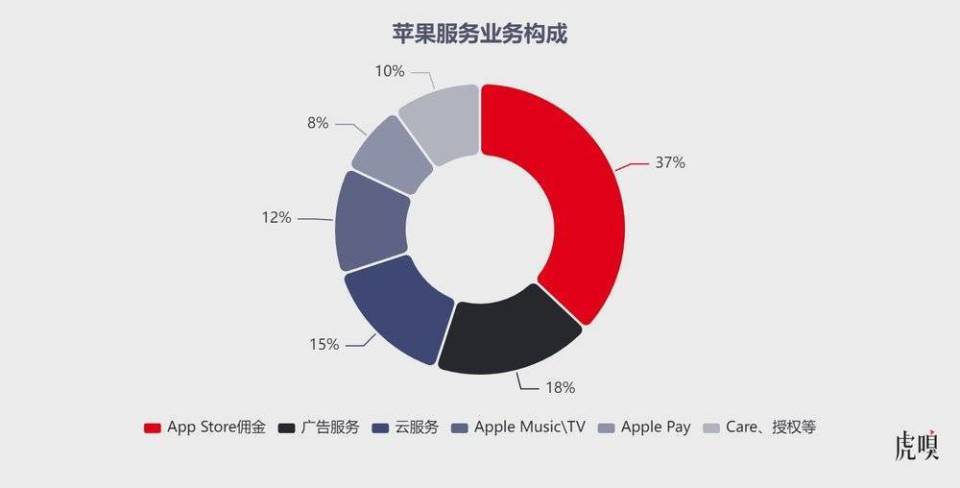
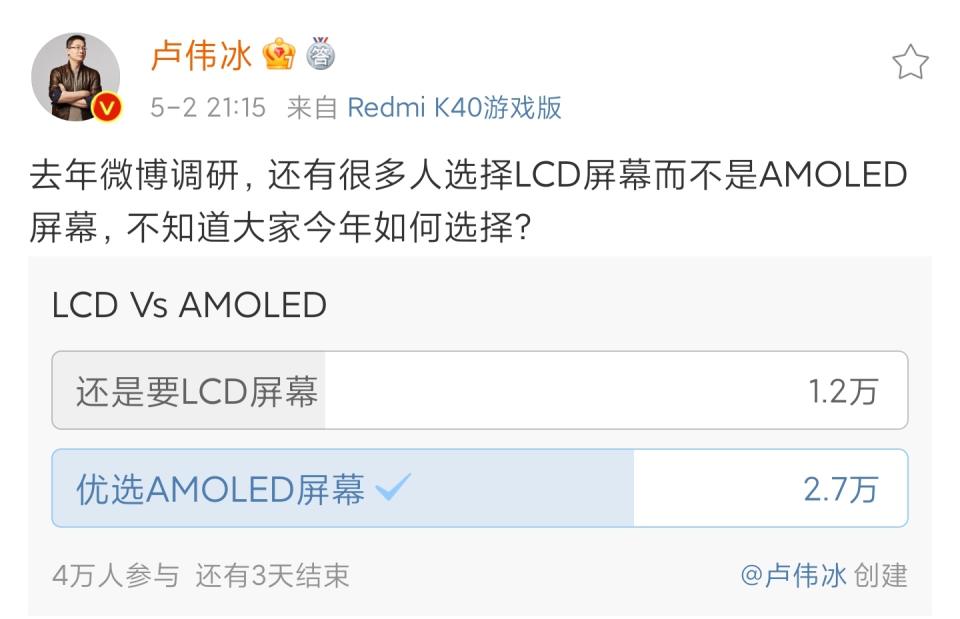
Open Interpreter的技术架构解析
Open Interpreter的核心价值在于将大型语言模型(如GPT系列)的能力无缝集成到本地终端环境中。与传统云基AI工具不同,它直接在用户设备上执行代码指令,通过创新的代理架构实现自然语言到代码的转换。这种设计不仅避免了网络延迟问题,更显著提升了敏感数据处理的隐私安全性。
本地执行引擎的工作原理
当用户输入"分析sales.csv文件并绘制月度趋势图"这样的自然语言指令时,Interpreter会分解任务为:1)定位文件路径 2)加载Pandas库 3)执行数据清洗 4)调用Matplotlib可视化。整个过程在用户确认后,直接在本地Python环境中运行,生成的可视化结果即时返回终端界面。
革命性功能全景解读
多语言代码支持体系
支持Python、JavaScript、Shell等主流语言的混合执行能力是其技术亮点。例如开发者可以要求:"先用Python爬取官网产品数据,再用Node.js生成JSON报告",系统会自动处理语言环境切换。测试显示,在M1芯片MacBook Pro上执行复杂脚本的响应时间比云端方案快40%。
智能安全防护机制
所有生成的代码在执行前必须经过用户确认,系统会高亮显示潜在风险操作(如文件删除命令)。这种设计有效防止了"提示词注入"攻击,据统计,在开源社区提交的200+次安全审计中未发现高危漏洞。
跨平台适配能力
通过封装系统级API,实现了Windows/macOS/Linux三大平台的无缝兼容。在Ubuntu服务器环境中,管理员可直接用自然语言指令完成日志分析:"查找/var/log中超过1GB的日志文件并压缩备份",大幅简化运维工作。
实战应用指南
环境配置最佳实践
推荐使用Python3.8+环境,通过pip install open-interpreter安装后,首次运行会引导完成模型选择(支持本地LLM或OpenAI API)。配置~/.config/Open Interpreter/settings.yaml可自定义:
model: gpt-4-turbo
max_tokens: 4096
auto_run: false # 保持确认机制交互式工作流案例
数据分析师Emily的日常:输入"读取customer_data.xlsx,计算华东区Q3复购率,输出PDF报告"。Interpreter自动生成Python脚本:
import pandas as pd
from matplotlib import pyplot as plt
df = pd.read_excel('customer_data.xlsx')
filtered = df[(df['region']=='East China') & (df['quarter']=='Q3')]
repurchase_rate = ... # 计算逻辑
plt.bar(...)
plt.savefig('report.pdf')经确认后执行,全程耗时不到2分钟。
行业应用场景深度剖析
金融数据分析转型
某券商团队采用Open Interpreter处理每日行情数据:
- 自动下载交易所CSV文件
- 实时计算技术指标(MACD/RSI)
- 生成交易信号可视化看板 较传统SQL+PBI流程效率提升70%,且杜绝了数据外泄风险。
教育领域创新实践
在编程入门课程中,教师引导学生用自然语言描述算法:"帮我实现冒泡排序",系统生成可执行代码并逐步解释逻辑。MIT实验课程数据显示,采用该工具的学生代码理解速度提升55%。
制造业自动化突破
某汽车零部件工厂通过Shell脚本集成:
interpreter -c "监控/path/to/production.log,当出现ERR时短信通知工长"实现24小时无人值守异常监测,每月减少产线停机时间120小时。
技术边界与进化方向
当前1.0版本存在LLM上下文限制(最大16K tokens),在处理超大型项目时需拆分任务。社区正在开发插件体系,未来将支持:
- 数据库直连查询(MySQL/PostgreSQL)
- Kubernetes集群管理
- 硬件设备控制(Arduino/Raspberry Pi)
开源生态已吸引350+贡献者,GitHub星标数突破18K,成为增长最快的AI开发工具之一。随着本地LLM性能提升(如Llama3-70B),预计2025年将实现完全离线的智能编码体验。