在人工智能技术飞速迭代的今天,大语言模型(LLM)的智商似乎越来越高,但它们的“记性”却依然令人捉急。明明在第一轮对话中详细告知了对海鲜的过敏禁忌,等到第五轮询问晚餐推荐时,模型却若无其事地推荐了一家海鲜餐厅;或者在咨询完售后问题后,被转接到另一个智能体,又不得不把问题描述从头再来一遍。这些尴尬的日常,折射出当前通用大模型普遍存在的“记忆缺陷”。这种缺陷不仅仅是用户体验上的小小瑕疵,更是制约AI从单纯的“工具级服务”迈向真正“认知级伙伴”的关键瓶颈。毕竟,一个记不住用户喜好、无法延续上下文的AI,很难称得上是智能。
现有技术架构下的记忆痛点
深入分析大模型“健忘”的根源,我们发现这并非单一的技术局限,而是现有架构下多重挑战的叠加。首先是单模型的知识遗忘问题。主流大模型的上下文窗口虽然已经扩展到了100k甚至200k tokens,但在长对话中,早期的关键信息依然容易被新的输入“挤出”。这种“挤出效应”导致模型在处理长序列任务时,往往顾头不顾尾,出现“答后忘前”的现象。对于需要长期记忆支持的任务来说,这种机制显然是不够的。
其次是多Agent环境下的记忆断层。在实际的商业应用中,往往是由多个智能体协同工作,分别负责咨询、售后、推荐等不同环节。然而,目前的架构大多让这些智能体各自维护独立的记忆空间,缺乏跨模块的记忆共享机制。这导致了严重的“数据孤岛”现象,用户在不同场景间切换时,不得不重复提供信息,不仅增加了沟通成本,也造成了Token资源的巨大浪费。
最后是语义解析的失真问题。人类的语言是复杂的,充满了模糊指代、口语化表达甚至多语种混用。现有的大模型在处理这些非标准化输入时,往往难以准确定位历史记忆中的相关信息,导致检索失败或答非所问。这些问题直接影响了大模型在C端用户群中的使用体验,使得AI在需要精准记忆的严肃场景——如医疗问诊、个性化教育、高端客服等——中难以发挥其应有的价值。
模拟人脑:构建AI的“海马体”机制
为了从根本上解决这些问题,业界进行了多种尝试。Meta FAIR实验室曾联合高校团队通过参数微调的方式来优化模型的记忆性能,虽然取得了一定进展,但由于新增参数容量有限,难以承载海量的新知识,甚至可能导致模型出现“灾难性遗忘”。美国和韩国的一些AI创业团队也探索过外挂向量数据库的方案,但往往因为检索延迟过高或语义匹配不准,无法满足实时交互的需求。
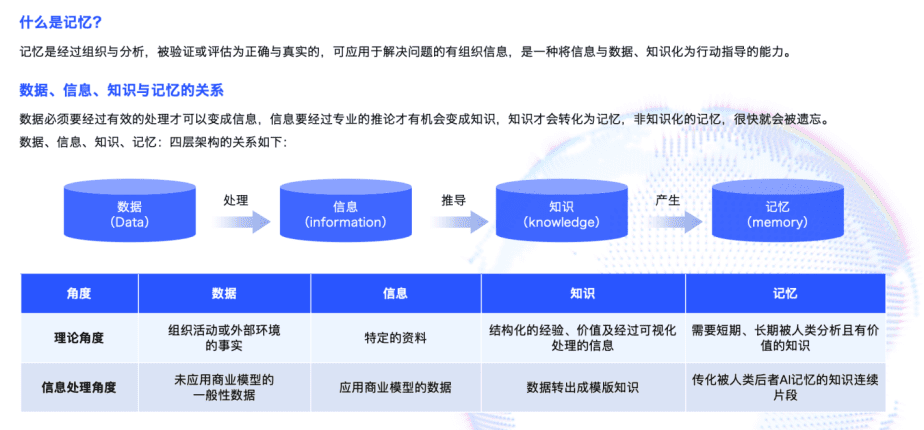
真正的突破,往往来自于对自然智慧的模仿。红熊AI推出的开源产品“记忆熊”(MemoryBear),选择了一条不同的道路:借鉴人类大脑的记忆原理,为AI构建一个类似于“海马体”的记忆中枢。人类的大脑之所以能拥有强大的记忆能力,关键在于海马体与大脑皮层的协作机制。海马体负责记忆的初步编码和短期存储,而大脑皮层则负责长期记忆的巩固和检索。
“记忆熊”正是基于这一原理,复刻了感知记忆、工作记忆、显性记忆、隐性记忆、情绪记忆五大模块,形成了一个从“数据输入”到“认知输出”的完整闭环。在这个体系中,“记忆熊”充当了大模型头脑中的“海马体”,掌管着记忆的形成、存储与调用。它不仅是一个被动的存储库,更是一个主动的信息处理器,能够对输入的信息进行感知、提炼、关联和遗忘,从而大幅减少模型的幻觉,提高应答的准确性与效率。
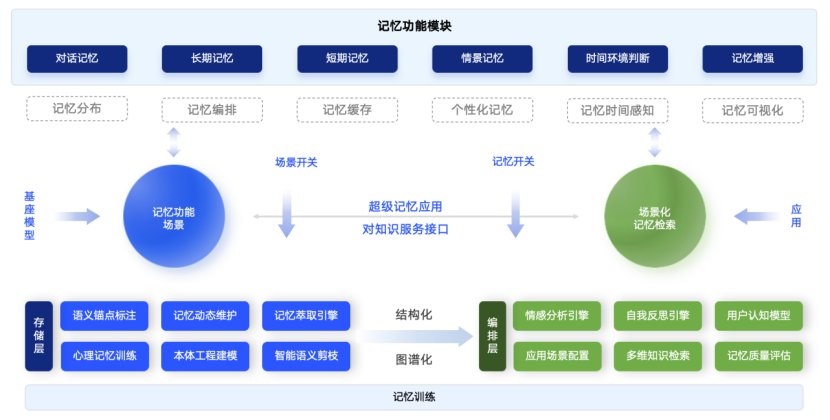
分层记忆架构与动态语义网络
“记忆熊”的核心技术优势,在于其独创的分层记忆体系。在显性记忆层,系统通过结构化数据库存储那些可以被主动调用的信息,例如用户的历史对话记录、行业知识库中的事实性数据。这一层支持精准的查询与检索,确保AI在需要时能够迅速找到“确切答案”。而在隐性记忆层,系统则将AI的行为习惯、任务技能与决策偏好存储在独立于大模型参数的外部组件中。这使得AI能够像人类拥有“肌肉记忆”一样,下意识且高效地处理重复性任务,从而在不占用显性认知资源的情况下优化行为模式。
更为创新的是其动态语义网络技术。传统的关键词匹配检索方式往往难以理解语言背后的深层含义,而“记忆熊”通过建立记忆之间的复杂关联,实现了联想式的记忆检索。例如,当AI检索到“咖啡”这个关键词时,能够通过语义网络联想到用户“早晨通勤”的习惯,并结合当前的天气数据,主动推荐冰咖啡或热咖啡。这种基于“语义网络模型”的技术,让AI具备了类似人类的联想能力,能够真正理解用户的隐含需求。
针对大模型处理高耗低效的问题,“记忆熊”研发了智能语义剪枝技术。在保持语义完整性的前提下,该技术能够精准地剔除冗余信息。实测数据显示,这一技术实现了97%的Token效率提升,并将语境偏移率降低了72%。同时,通过语义锚点标注和多维检索引擎,系统有效抑制了幻觉的生成,显著提高了模型输出的可靠性。
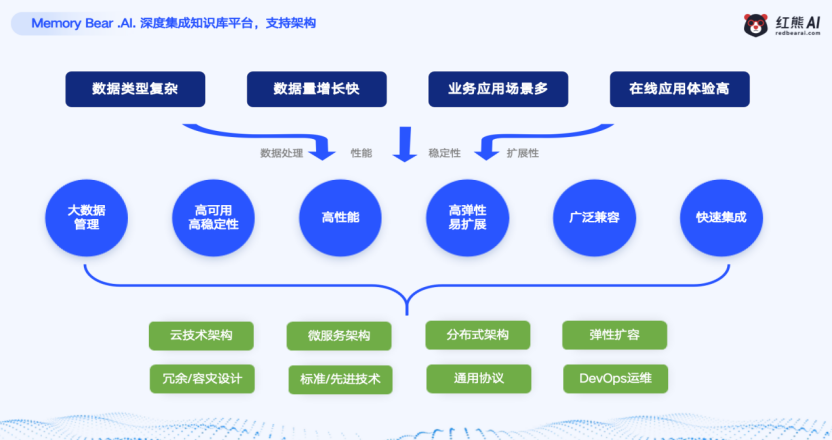
自我反思与跨Agent协作
人类的记忆并非一成不变,而是在睡眠中不断被整理和强化。受此启发,“记忆熊”引入了自我反思引擎。该引擎借鉴人类睡眠中强化记忆的原理,在离线周期中对已有的记忆进行梳理、重排和重要度重估。这种机制使得AI能够在交互过程中不断学习,并在静默期完成知识的内化与巩固,从而提升其长期表现。结合记忆遗忘引擎,系统能够在持续进行增量学习的同时保持系统的稳定性,巧妙地平衡了学习效率与抗遗忘能力之间的关系。
在多Agent协作方面,“记忆熊”通过记忆共享引擎彻底解决了“数据孤岛”难题。它构建了一个统一的记忆中枢,打破不同智能体之间的壁垒。当用户在咨询、售后、推荐等不同场景之间切换时,对话状态、历史偏好、关键诉求等信息能够实现无缝传递,用户无需再进行重复描述。这种“一次沟通,全程复用”的体验,极大地提升了交互的流畅度和连贯性。
商业落地与实战效能
技术的价值最终要靠应用场景来检验。在权威的LOCOMO数据集测试中,“记忆熊”的核心指标全面超越了Mem0、Zep、LangMem等现有主流方案,展现了压倒性的技术优势。更值得一提的是,基于图谱的版本将搜索延迟p50控制在0.637秒,成功破解了行业中长期存在的“高准确必伴随高延迟”的魔咒。
在实际应用中,红熊AI Agent互动服务平台接入该产品后,实现了98.4%的AI自助解决率和70%的人工替代率,真正为企业创造了可量化的商业价值。在智能客服场景下,“记忆熊”能够为每位用户创建动态记忆图谱,实时回溯过往的交互历史与情感状态,并将这些信息共享给所有客服Agent。这使得服务从被动的“问题解答”转变为主动的“关怀预测”,显著提升了用户满意度。
在精准营销领域,产品实现了从“猜你喜欢”到“我记得你喜欢”的跨越。通过构建用户兴趣记忆图谱,系统能够追踪用户从首次点击到复购的完整旅程,进行超个性化的推荐。在AI教育场景中,它打造了拥有终身记忆的AI导师,能够记住学生的每一次答题、犹豫以及偏好的学习方式,真正落实因材施教的教育理念。而在数字医疗领域,产品创建的集中化病史记忆,整合了症状变化、过敏史、既往用药等关键信息,为医生提供了全面的患者视图,有效解决了病史分散、复诊重复沟通的行业痛点。
开源策略与未来展望
目前,红熊AI已经正式开源了“记忆熊”的核心技术框架。这种开源策略并非放弃竞争力,正如其创始人温德亮所言,真正的竞争力在于持续创新和精准抓住客户痛点的能力。通过开源,红熊AI旨在吸引更多的开发者参与到记忆科学的生态建设中来,共同推动AI认知能力的升级。
展望未来,红熊AI计划进一步推动“记忆熊”在更多垂直领域的落地,深化与多模态大模型的融合,并优化订阅制服务模式。预计明年通过订阅制服务实现50倍的业务增长。长期来看,其愿景是让AI从“工具级服务”真正迈向“伙伴级服务”,实现“无处不在,又无处可见”的智能体验。通过持续深耕记忆科学,赋予AI像人类一样的记忆能力,我们将见证人工智能向更高阶认知智能的迈进,让AI真正成为理解用户、持续学习、共同成长的可靠伙伴。